10 | 多路归并排序:如何解决搜索引擎中的大数据排序问题?
你好,我是胡光,欢迎回来。
上节课,我们学习了归并排序算法的基本思路,由归并排序算法我们了解了分治算法的基本思想,并且配合归并排序的代码框架解决了求解逆序数的问题。
其实,归并排序能够解决的问题非常多,今天,我们把目光放到工业界的搜索引擎上,来说说怎么利用归并排序解决大数据排序问题。
老规矩,我先给你出一道题:假设给你一组数据让你排序,你会怎么做?我们可以轻松回答出来,使用快速排序、堆排序或者归并排序都可以完成这个任务。那如果我告诉你这组数据有4TB,也就是说,现在有 4096GB 大小的数据正在等你排序,你又该怎么做呢?
这时候你会发现,之前我们学习的排序算法都不灵了。因为我们之前所掌握的算法,好像都需要先将数据存放在内存中才能进行操作,而现在要处理的数据量太大,无法全部载入内存中。内存都存不下的数据,我们肯定操作不了。
那你可能有疑问了,什么情况下,我们才会遇到数据量这么大的排序问题呢?其实很容易就能想到,像是搜索引擎、推荐系统、广告引擎等等都需要处理这么大的排序问题。那它们是怎么做的呢?下面,我们就以搜索引擎为例,一起来看看。
搜索引擎中的倒排索引
搜索引擎想必你不陌生,会使用搜索已经是现代人必不可少的生存技能之一了。我们在使用百度或者谷歌这类搜索引擎的时候,可以利用网页内容搜索相关网页,也是利用内容进行索引。能够完成这种搜索方式的最大功臣,就是搜索引擎底层的倒排索引结构。近几年来,搜索引擎其实也开始引入很多前沿的技术,比如知识图谱这种图存储结构,用来补充倒排索引在功能上的缺陷。
倒排索引结构对于搜索引擎来说是非常重要的,可以说是搜索引擎的底层核心。那在建立倒排索引的过程中,非常重要的一步就是对大量的数据进行排序,而且它要处理数据量远大于内存的大小。
接下来,我们来详细说说倒排索引的结构。
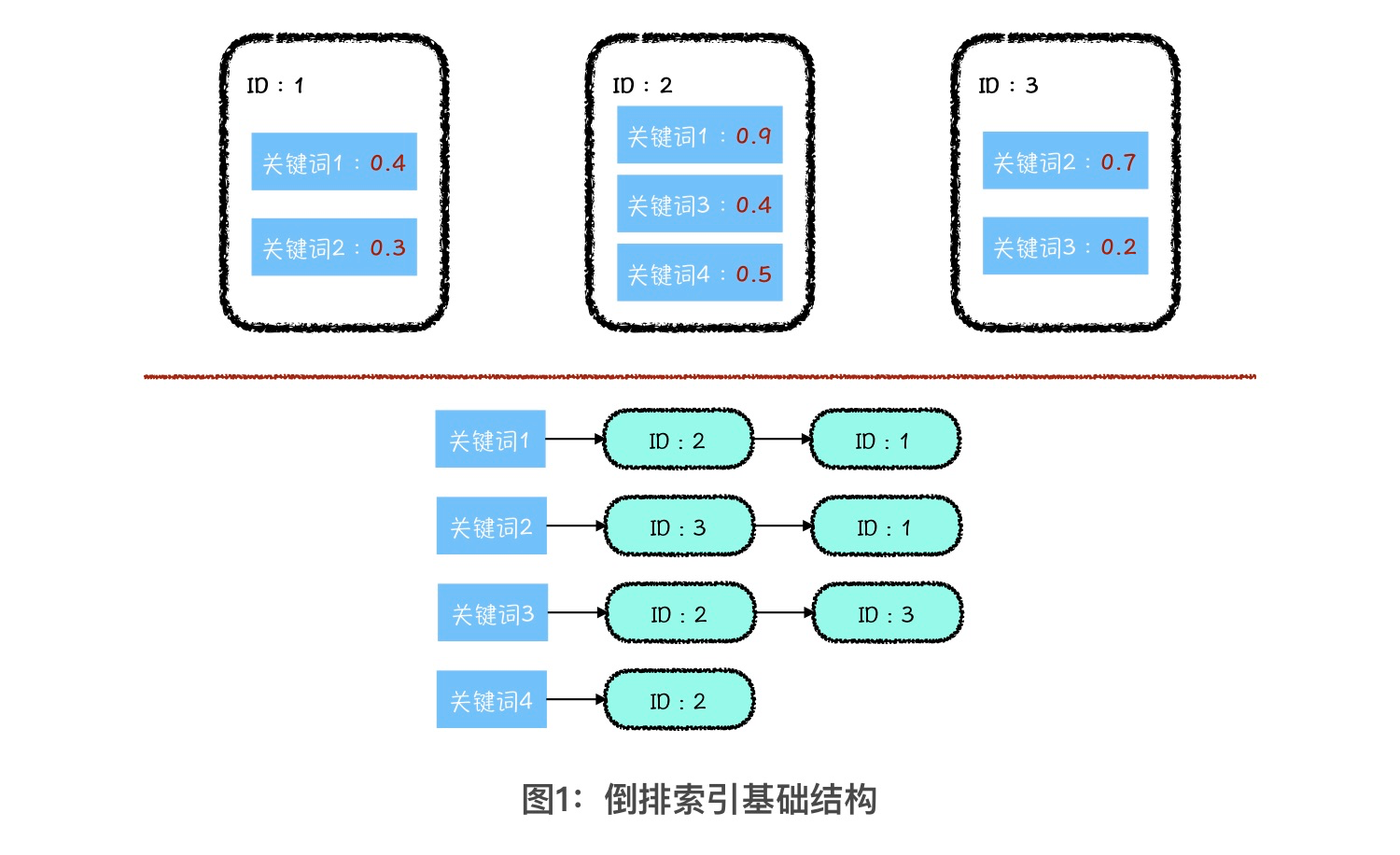
假设,现在有三个网页,编号依次是1、2、3。通过分析网页内容,我们在每个网页里面都能提取出若干可以代表该网页的关键词,以及每个关键词和该网页的一个相关程度。网页1中包含关键词1和2,相关程度分别是 0.4 与 0.3;网页2中包含关键词1、3和4,相关程度分别是0.9、0.4 和 0.5;网页3中包含关键词2和3,相关度分别是0.7和0.2。
倒排索引就是以关键词作为索引项,再把与关键词相关的网页按照其与关键词的相关程度,从高到低排序所形成的索引结构。这句话比较绕,具体的你可以参考上图进行理解。
这里,我再举个例子,让你理解倒排索引的作用。当我们搜索关键词3的时候,在倒排索引中,相关网页是网页2和3,搜索引擎会按照相关程度将网页从前到后展现在我们的页面上。那关键词与网页的相关程度到底是怎么算出来的?可用的算法可以说是五花八门了,其中最简单的就是 TF-IDF。你可以自己搜索一下,来了解相关的内容。
通过这个案例我们知道,建立倒排索引的过程中,我们要根据网页与关键词的相关程度进行排序,而这个排序量就属于大数据排序场景,一般内存是装不下的。拿教育这个关键词举例,在百度上搜索到的网页数量就有1亿个,如果每个文档的数据量是1kb,光这一个关键词涉及的排序数据量就是 100GB,当然这还是保守估计。
那么,这种大数据排序的问题应该怎么解决呢?接下来,我们就来解决这个问题。
多路归并排序
首先,我们来理解两个概念:内部排序 与 外部排序。
所谓内部排序,就是在内存中进行的排序,比如,我们之前学过的快速排序和堆排序。快速排序中每一轮的 partition 操作和递归操作,其实都是在内存中完成的。那堆排序中,建堆以及最后弹出元素调整的过程,也都需要元素在内存中。
但是,在对大数据进行排序的时候,数据是无法一次性装进内存的,需要分成若干次。因此,外部排序就是将待排序数据先分割成若干个可以存进内存的小文件,再对这若干个小文件分别排序,最后合并成若干个有序小文件的过程。
外部排序的过程,是不是听着有点儿像我们学过的归并排序的升级版?没错,归并排序在合并数据的时候,合并的是两个有序数组,所以准确来说它应该叫**二路归并排序算法。**而外部排序合并的是多个有序文件,其实我们也可以把它们看成是多个有序数组。那将多个有序数组合并成一个有序数组的算法,就叫做多路归并排序,也就是所谓的归并排序的升级版。
基于此,我们其实可以把二路归并排序当作是多路归并排序的一个特例。
我们上节课学习的归并排序,准确来说叫做二路归并排序,而这种所谓归并排序的升级版,名字就叫做多路归并排序,而二路归并排序就是多路归并排序的一个特例。
那我们就可以通过二路归并排序,推导出多路归并排序的过程。因此,我们就可以通过二路归并排序,推导出多路归并排序的过程。
我们先回忆一下,二路归并排序算法的合并过程。在将两个有序数组合并成一个的时候,每次我们都是在两个数组头部选取一个最小值放入到合并数组中。因此,多路归并排序算法就是将多个有序数组合并成一个,在合并的过程中,每次从多个数组的头部选择一个最小值加入到合并数组中。这里的数组,你可以理解成是文件或者集合。
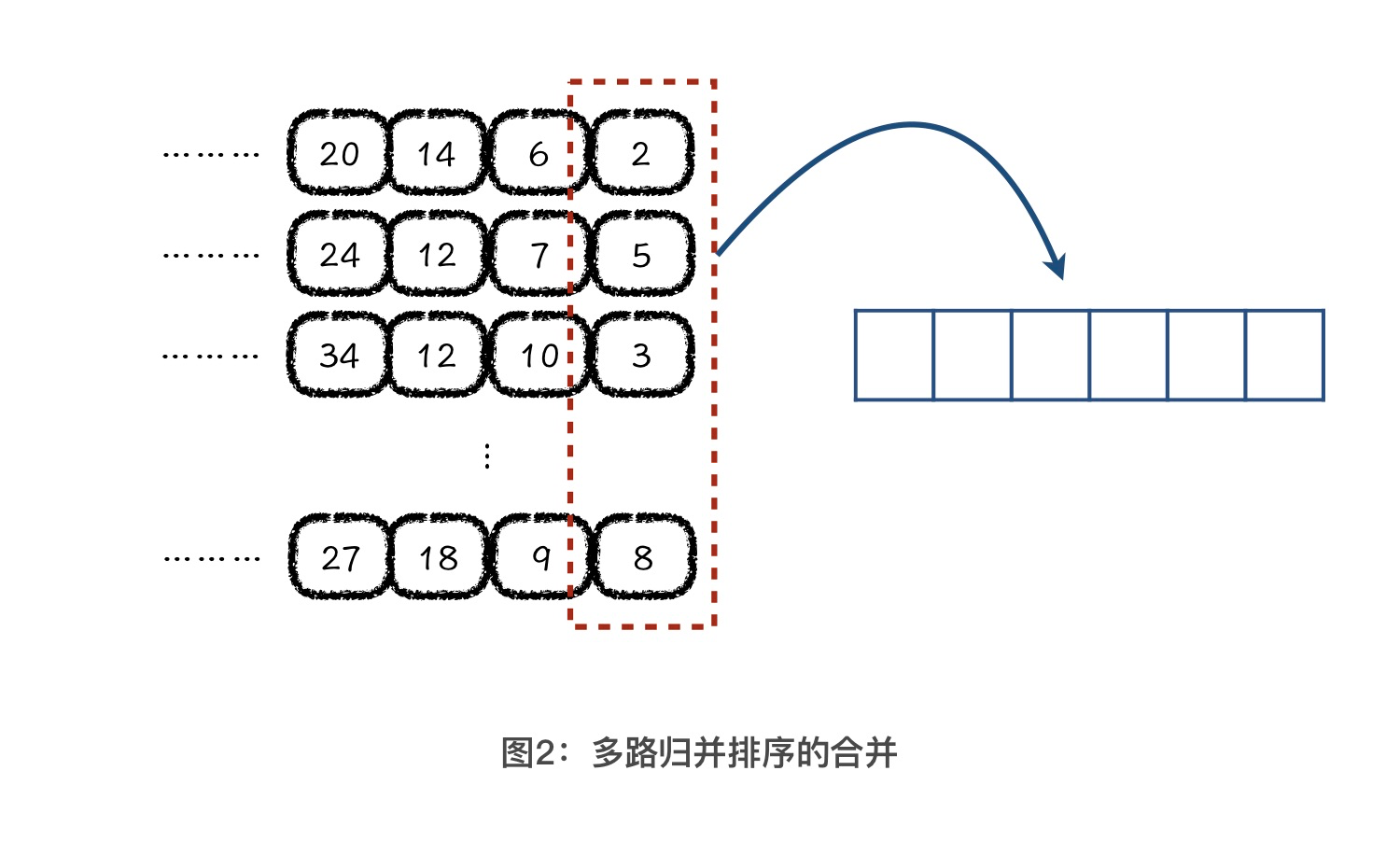
结合上图,红色虚线框内部是所有待合并数组的头部元素,每一次我们都从这个红色的集合中选择一个最小值放入到合并数组中,之后还会有一个新的元素进入到红色虚线框内。
这一步就是考查你算法思维的时候了,你觉得对于红色虚线框内部的元素,我们应该用什么数据结构进行维护?答案是一个支持添加元素和弹出最值元素的数据结构,这是不是和我们之前讲到的堆的性质是一致的?
好,其实到这里,今天的问题我们就解决了,多路归并是不是很好理解?在这里,我还想再强调一下,我们在学习数据结构的时候,学习的是每种数据结构适用的问题性质,只有扎实地掌握了每种数据结构所适用的问题性质,你才能真正具备运用数据结构解决实际问题的能力。
课程小结
在今天的课程中,我们在原本数据排序问题的基础上,增加了数据量,提出了大数据场景下的数据排序问题。面对这种无法一次性读入内存的数据排序问题,我们通常是将数据,分割成若干个可以载入内存的部分分别排序,并且将排序结果写入到相关文件中,最后我们再对这些有序文件执行合并操作,合并操作这一步可能需要借助我们之前学过的堆结构。
多路归并排序最重要的应用场景之一,就是搜索引擎中的倒排索引结构,相信通过今天的内容也能够帮助你理解倒排索引。
如果说,通过今天课程我只想让你记住一句话,我想那应该是:学习每种数据结构能够解决问题的性质,才是掌握数据结构的核心法门。
课后练习
最后,你能参考前几堂课的代码,用你熟悉的语言来完成本堂课多路归并排序的算法代码吗?
欢迎把你的实现代码和疑问写在留言区,我们一起讨论,也欢迎你把这节课分享给你的朋友。好了,今天就到这里了,我是胡光,我们下节课见!