38 | 加餐8:Java程序从虚拟机迁移到Kubernetes的一些坑
你好,我是朱晔,我们又见面了。结课并不意味着结束,我非常高兴能持续把好的内容分享给你,也希望你能继续在留言区与我保持交流,分享你的学习心得和实践经验。
使用Kubernetes大规模部署应用程序,可以提升整体资源利用率,提高集群稳定性,还能提供快速的集群扩容能力,甚至还可以实现集群根据压力自动扩容。因此,现在越来越多的公司开始把程序从虚拟机(VM)迁移到Kubernetes了。
在大多数的公司中,Kubernetes集群由运维来搭建,而程序的发布一般也是由CI/CD平台完成。从虚拟机到Kubernetes的整个迁移过程,基本不需要修改任何代码,可能只是重新发布一次而已。所以,我们Java开发人员可能对迁移这个事情本身感知不强烈,认为Kubernetes只是运维需要知道的事情。但是程序一旦部署到了Kubernetes集群中,在容器环境中运行,总是会出现各种各样之前没有的奇怪的问题。
今天的加餐,就让我们一起看下这其中大概会遇到哪些“坑”,还有相应的“避坑方法”。
Pod IP不固定带来的坑
Pod是Kubernetes中能够创建和部署应用的最小单元,我们可以通过Pod IP来访问到某一个应用实例,但需要注意的是,如果没有经过特殊配置,Pod IP并不是固定不变的,会在Pod重启后会发生变化。
不过好在,通常我们的Java微服务都是没有状态的,我们并不需要通过Pod IP来访问到某一个特定的Java服务实例。通常来说,要访问到部署在Kubernetes中的微服务集群,有两种服务发现和访问的方式:
- 通过Kubernetes来实现。也就是通过Service进行内部服务的互访,通过Ingress从外部访问到服务集群。
- 通过微服务注册中心(比如Eureka)来实现。也就是服务之间的互访通过客户端负载均衡后+直接访问Pod IP进行,外部访问到服务集群通过微服务网关转发请求。
使用这两种方式进行微服务的访问,我们都没有和Pod IP直接打交道,也不会把Pod IP记录持久化,所以一般不需要太关注Pod IP变动的问题。不过,在一些场景下,Pod IP的变动会造成一些问题。
之前我就遇到过这样的情况:某任务调度中间件会记录被调度节点的IP到数据库,随后通过访问节点IP查看任务节点执行日志的时候,如果节点部署在Kubernetes中,那么节点重启后Pod IP就会变动。这样,之前记录在数据库中的老节点的Pod IP必然访问不到,那么就会发生无法查看任务日志的情况。
遇到这种情况,我们应该怎么做呢?这时候,可能就需要修改这个中间件,把任务执行日志也进行持久化,从而避免这种访问任务节点来查看日志的行为。
总之,我们需要意识到Pod IP不固定的问题,并且进行“避坑操作”:在迁移到Kubernetes集群之前,摸排一下是否会存在需要通过IP访问到老节点的情况,如果有的话需要进行改造。
程序因为OOM被杀进程的坑
在Kubernetes集群中部署程序的时候,我们通常会为容器设置一定的内存限制(limit),容器不可以使用超出其资源limit属性所设置的资源量。如果容器内的Java程序使用了大量内存,可能会出现各种OOM的情况。
- 第一种情况,是OS OOM Kill问题。如果过量内存导致操作系统Kernel不稳定,操作系统可能就会杀死Java进程。这时候,你能在操作系统/var/log/messages日志中找到类似oom_kill_process的关键字。
- 第二种情况,是我们最常遇到的Java程序的OOM问题。程序超出堆内存的限制申请内存,导致Heap OOM,后续可能会因为健康检测没有通过被Kubernetes重启Pod。
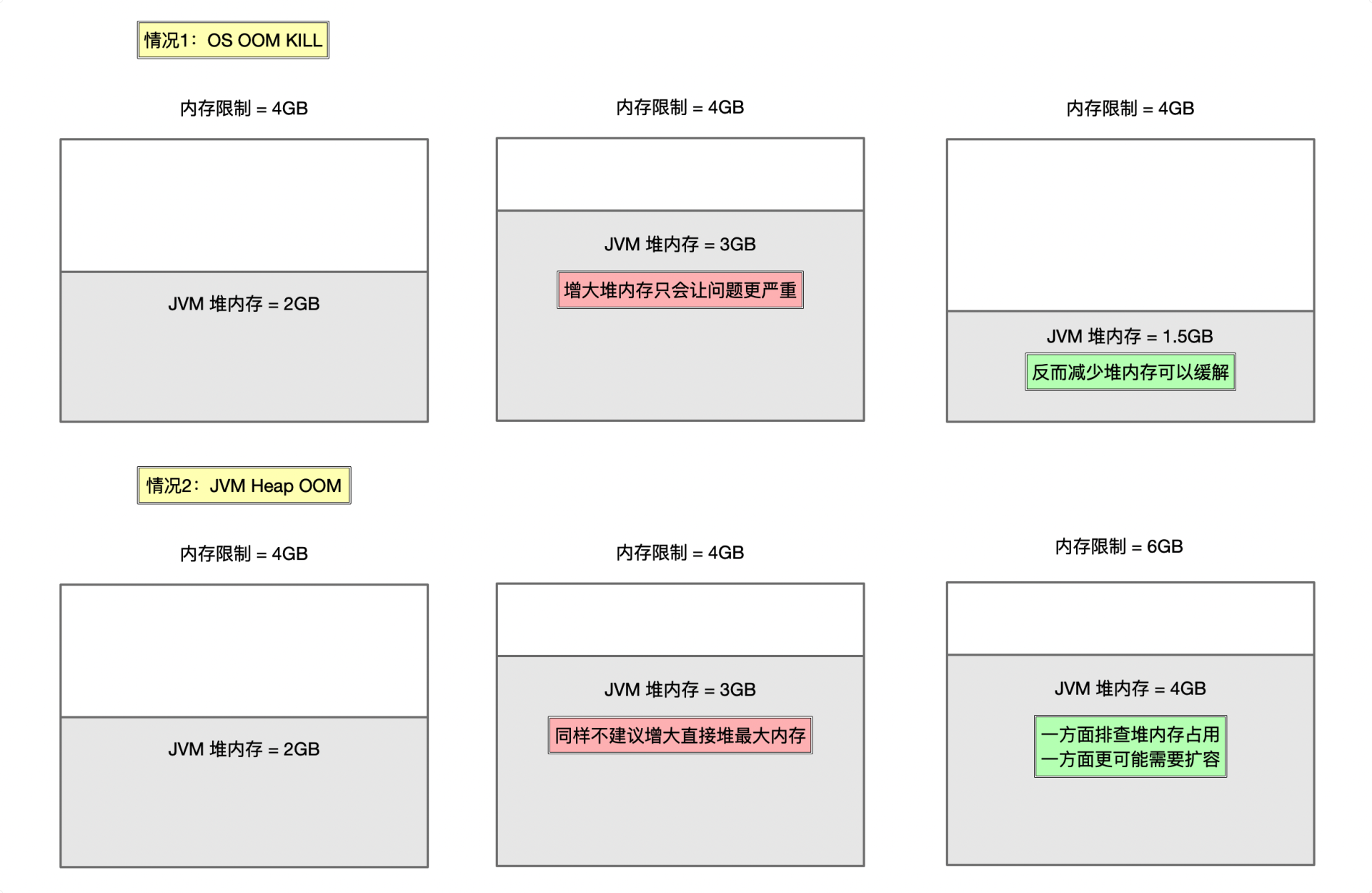
在Kubernetes中部署Java程序时,这两种情况都很常见,表现出的症状也都是OOM关键字+重启。所以,当运维同学说程序因为OOM被杀死或重启的时候,我们一定要和运维同学一起去区分清楚,到底是哪一种情况,然后再对症处理。
对于情况1,问题的原因往往不是Java堆内存不够,更可能是程序使用了太多的堆外内存,超过了内存限制。这个时候,调大JVM最大堆内存只会让问题更严重,因为堆内存是可以通过GC回收的。我们需要分析Java进程哪部分区域内存占用过大,是不是合理,以及是否可能存在内存泄露问题。Java进程的内存占用除了堆之外,还包括
- 直接内存
- 元数据区
- 线程栈大小 Xss * 线程数
- JIT代码缓存
- GC、编译器使用额外空间
- ……
我们可以使用NMT打印各部分区域大小,从而判断到底是哪部分内存区域占用了过多内存,或是可能有内存泄露问题:
java -XX:NativeMemoryTracking=smmary/detail -XX:+UnlockDiagnosticVMOptions -XX:+PrintNMTStatistics
**如果你确认OOM是情况2,那么我同样不建议直接调大堆内存的限制,防止之后再出现情况1。**我会更建议你把堆内存限制为容器内存限制的50%~70%,预留出足够多的内存给堆外和OS核心。如果需要扩容堆内存的话,那么也需要同步扩容容器的内存limit。此外,也需要通过Heap Dump(你可以回顾下第35讲的相关内容)等手段来排查为什么堆内存占用会这么大,排除潜在的内存泄露的可能性。
内存和CPU资源配置不适配容器的坑
刚刚我们提到了,堆内存扩容需要结合容器内存limit同步进行。其实,我们更希望的是,Java程序的堆内存配置能随着容器的资源配置,实现自动扩容或缩容,而不是写死Xmx和Xms。这样一来,运维同学可以更方便地针对整个集群进行扩容或缩容。
对于JDK>8u191的版本,我们可以设置下面这些JVM参数,来让JVM自动根据容器内存限制来设置堆内存用量。比如,下面配置相当于把Xmx和Xms都设置为了容器内存limit的50%:
XX:MaxRAMPercentage=50.0 -XX:InitialRAMPercentage=50.0 -XX:MinRAMPercentage=50.0
接下来,我们看看CPU资源配置不适配容器的坑,以及对应的解决方案。
对于CPU资源的使用,我们主要需要注意的是,代码中的各种组件甚至是JVM本身,会根据CPU数来配置并发数等重要参数指标,那么:
如果这个值因为JVM对容器的兼容性问题取到了Kubernetes工作节点的CPU数量,那么这个数量可能就不是4或8,而是128以上,进而导致并发数过高。
对于JDK>8u191的版本可能会对容器兼容性较好,但是其获取到的Runtime.getRuntime().availableProcessors() 其实是request的值而不是limit的值(比如我们设置request为2、limit为8、CICompilerCount和ParallelGCThreads可能只是2),那么可能并发数就会过低,进而影响JVM的GC或编译性能。
所以,我的建议是:第一,通过-XX:+PrintFlagsFinal开关,来确认ActiveProcessorCount是不是符合我们的期望,并且确认CICompilerCount、ParallelGCThreads等重要参数配置是否合理。
第二,直接设置CPU的request和limit一致,或是对于JDK>8u191的版本可以通过-XX:ActiveProcessorCount=xxx直接把ActiveProcessorCount设置为容器的CPU limit。
Pod重启以及重启后没有现场的坑
除非宿主机有问题,否则虚拟机不太会自己重启或被重启,而Kubernetes中Pod的重启绝非小概率事件。在存活检测不通过、Pod重新进行节点调度等情况下,Pod都会进行重启。对于Pod的重启,我们需要关注两个问题。
第一个问题是,分析Pod为什么会重启。
其中,除了“程序因为OOM被杀进程的坑”这部分提到的OOM的问题之外,我们还需要关注存活检查不通过的情况。
Kubernetes有readinessProbe和livenessProbe两个探针,前者用于检查应用是否已经启动完成,后者用于持续探活。一般而言,运维同学会配置这2个探针为一个健康检测的断点,如果健康检测访问一次需要消耗比较长的时间(比如涉及到存储或外部服务可用性检测),那么很可能可以通过readinessProbe的检查但不通过livenessProbe检查(毕竟我们通常会为readinessProbe设置比较长的超时时间,而对于livenessProbe则没有那么宽容)。此外,健康检测也可能会受到Full GC的干扰导致超时。所以,我们需要和运维同学一起确认livenessProbe的配置地址和超时时间设置是否合理,防止偶发的livenessProbe探活失败导致的Pod重启。
第二个问题是,要理解Pod和虚拟机不同。
虚拟机一般都是有状态的,即便部署在虚拟机内的Java程序重启了,我们始终能有现场。而对于Pod重启来说,则是新建一个Pod,这就意味着老的Pod无法进入。因此,如果因为堆OOM问题导致重启,我们希望事后查看当时OS的一些日志或是在现场执行一些命令来分析问题,就不太可能了。
所以,我们需要想办法在Pod关闭之前尽可能保留现场,比如:
- 对于程序的应用日志、标准输出、GC日志等可以直接挂载到持久卷,不要保存在容器内部。
- 对于程序的堆栈现场保留,可以配置-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath在堆OOM的时候生成Dump;还可以让JVM调用任一个shell脚本,通过脚本来保留线程栈等信息:
-XX:OnOutOfMemoryError=saveinfo.sh
- 对于容器的现场保留,可以让运维配置preStop钩子,在Pod关闭之前把必要的信息上传到持久卷或云上。
重点回顾
今天,我们探讨了Java应用部署到Kubernetes集群会遇到的4类问题。
第一类问题是,我们需要理解应用的IP会动态变化,因此要在设计上解除对Pod IP的强依赖,使用依赖服务发现来定位到应用。
第二类问题是,在出现OOM问题的时候,首先要区分OOM的原因来自Java进程层面还是容器层面。如果是容器层面的话,我们还需要进一步分析到底是哪个内存区域占用了过多内存,定位到问题后再根据容器资源设置合理的JVM参数或进行资源扩容。
第三类问题是,需要确保程序使用的内存和CPU资源匹配容器的资源限制,既要确保程序所“看”到的主机资源信息是容器本身的而不是物理机的,又要确保程序能尽可能随着容器扩容而扩容其资源限制。
第四类问题是,我们需要重点关注程序非发布期重启的问题,并且针对Pod的重启问题做好现场保留的准备工作,排除资源配置不合理、存活检查不通过等可能性,以避免因为程序频繁重启导致的偶发性能问题或可用性问题。
只有解决了这些隐患,才能让Kubernetes集群更好地发挥作用。
思考与讨论
在你的工作中,还遇到过Java+Kubernetes中的其他坑吗?
我是朱晔,欢迎在评论区与我留言分享,也欢迎你把今天的内容分享给你的朋友或同事,一起交流。