09 | 索引更新:刚发布的文章就能被搜到,这是怎么做到的?
你好,我是陈东。
在前面的课程中,我们讲到,倒排索引是许多检索系统的核心实现方案。比如,搜索引擎对万亿级别网页的索引,就是使用倒排索引实现的。我们还讲到,对于超大规模的网页建立索引会非常耗时,工业界往往会使用分布式技术来并行处理。
对于发布较久的网页,搜索引擎可以有充足的时间来构建索引。但是一些新的网页和文章,往往发布了几分钟就可以被用户搜索到。这又是怎么做到的呢?今天,我们就来聊一聊这个问题。
工业界如何更新内存中的索引?
我们先来看这么一个问题:如果现在有一个小规模的倒排索引,它能完全加载在内存中。当有新文章进入内存的时候,倒排索引该如何更新呢?这个问题看似简单,但是实现起来却非常复杂。
我们能想到最直接的解决思路是,只要解析新文章有哪些关键词,然后将文章ID加入倒排表中关键词对应的文档列表即可。没错,在没有其他用户使用的情况下,这样的方法是可行的。但如果你有过一定的工程经验,你就会知道,在实际应用中,必然会有多个用户同时访问这个索引。
这个时候,如果我们直接更新倒排索引,就可能造成用户访问错误,甚至会引发程序崩溃。因此,一般来说,我们会对倒排表加上“读写锁”,然后再更新。但是,加上“锁”之后会带来频繁的读写锁切换,整个系统的检索效率会比无锁状态有所下降。
因此,为了使得系统有更好的性能,在工业界的实现中,我们会使用一种叫做“Double Buffer(双缓冲)机制”的解决方案,使得我们可以在无锁状态下对索引完成更新。
所谓“Double Buffer”,就是在内存中同时保存两份一样的索引,一个是索引A,一个是索引B。我们会使用一个指针p指向索引A,表示索引A是当前可访问的索引。那么用户在访问时就会通过指针p去访问索引A。这个时候,如果我们要更新,只更新索引B。这样,索引A和索引B之间就不存在读写竞争的问题了。因此,在这个过程中,索引A和索引B都可以保持无锁的状态。
那更新完索引B之后,我们该如何告知用户应该来访问索引B呢?这时候,我们可以将指针p通过原子操作(即无法被打断的最细粒度操作,在Java和C加加11等语言中都有相应实现)从A直接切换到B上。接着,我们就把索引B当作“只读索引”,然后更新索引A。
通过这样的机制,我们就能同时维护两个倒排索引,保持一个读、一个写,并且来回切换,最终完成高性能的索引更新。不过,为了避免切换太频繁,我们并不是每来一条新数据就更新,而是积累一批新数据以后再批量更新。这就是工业界常用的Double Buffer机制。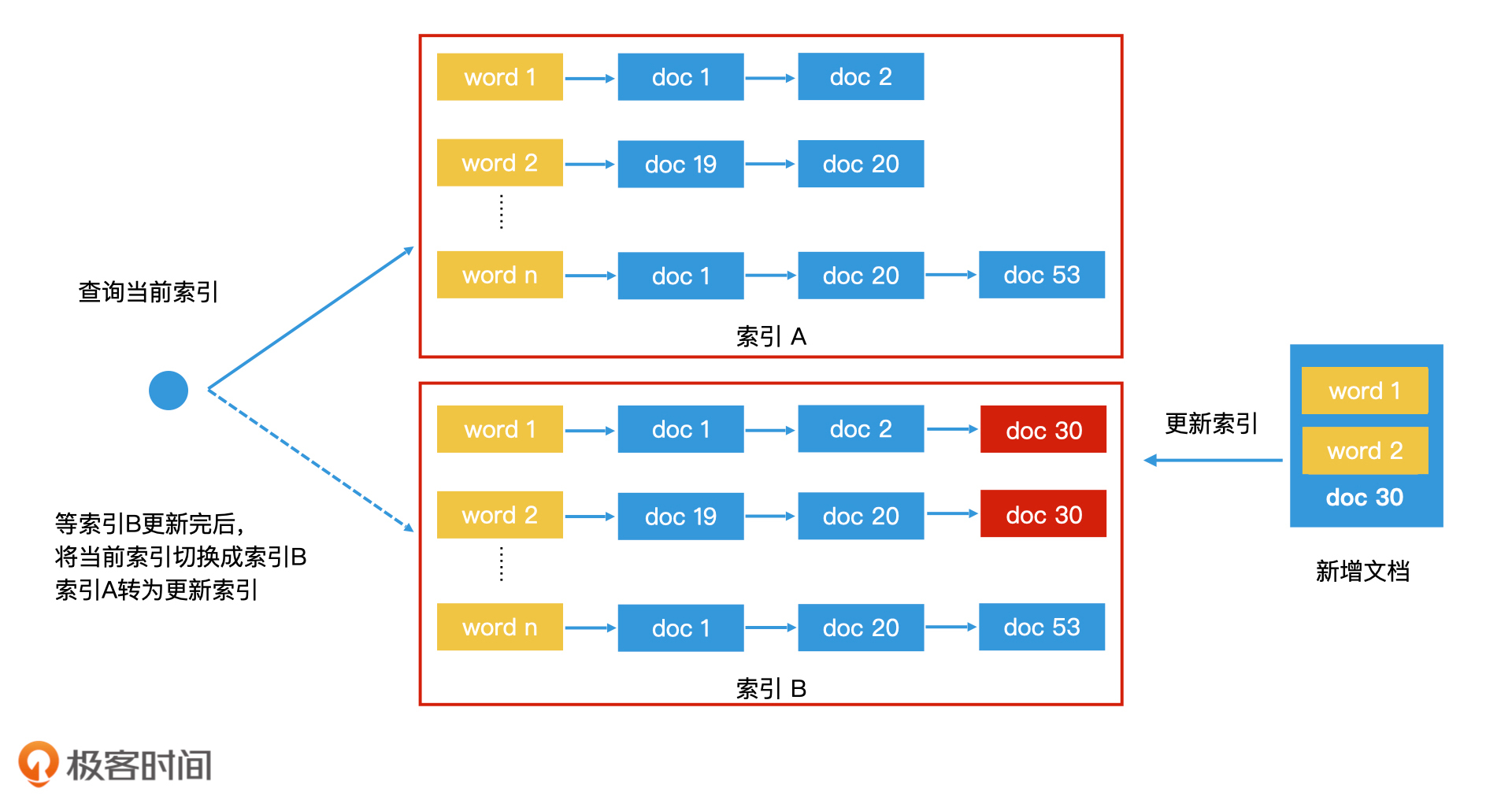
用Double Buffer机制更新索引
用Double Buffer机制更新索引是一个高效的方案,追求检索性能的应用场景常常会使用这种方案。但是对于索引到了一定量级的应用而言,使用Double Buffer会带来翻倍的内存资源开销。比如说,像搜索引擎这样万亿级网页的索引规模,数据大部分存储在磁盘上,更是无法直接使用Double Buffer机制进行更新的。因此,我们还是需要寻找其他的解决方案。
如何使用“全量索引结合增量索引”方案?
对于大规模的索引更新,工业界常用“全量索引结合增量索引”的方案来完成。下面,我们就一起来探讨一下,这个方案是如何实现索引更新的。
首先,系统会周期性地处理全部的数据,生成一份完整的索引,也就是全量索引。这个索引不可以被实时修改,因此为了提高检索效率,我们可以不加“锁”。那对于实时更新的数据我们应该怎样处理呢?我们会将新接收到的数据单独建立一个可以存在内存中的倒排索引,也就是增量索引。当查询发生的时候,我们会同时查询全量索引和增量索引,将合并的结果作为总的结果输出。这就是“全量索引结合增量索引”的更新方案。
其实这个方案还能结合我们上面讲的Double Buffer机制来优化。因为增量索引相对全量索引而言会小很多,内存资源消耗在可承受范围,所以我们可以使用Double Buffer机制对增量索引进行索引更新。这样一来,增量索引就可以做到无锁访问。而全量索引本身就是只读的,也不需要加锁。因此,整个检索过程都可以做到无锁访问,也就提高了系统的检索效率。
“全量索引结合增量索引”的检索方案,可以很好地处理新增的数据。那对于删除的数据,如果我们不做特殊处理,会有什么问题呢?下面,我们一起来分析一下。
假设,一个数据存储在全量索引中,但是在最新的实时操作中,它被删除了,那么在增量索引中,这个数据并不存在。当我们检索的时候,增量索引会返回空,但全量索引会返回这个数据。如果我们直接合并这两个检索结果,这个数据就会被留下作为检索结果返回,但是这个数据明明已经被删除了,这就会造成错误。
要解决这个问题,我们就需要在增量索引中保留删除的信息。最常见的解决方案是增加一个删除列表,将被删除的数据记录在列表中,然后检索的时候,我们将全量倒排表和增量倒排表的检索结果和删除列表作对比。如果结果数据存在于删除列表中,就说明该数据是无效的,我们直接删除它即可。
因此,完整的“全量索引结合增量索引”检索方案,需要在增量索引中保存一个删除列表。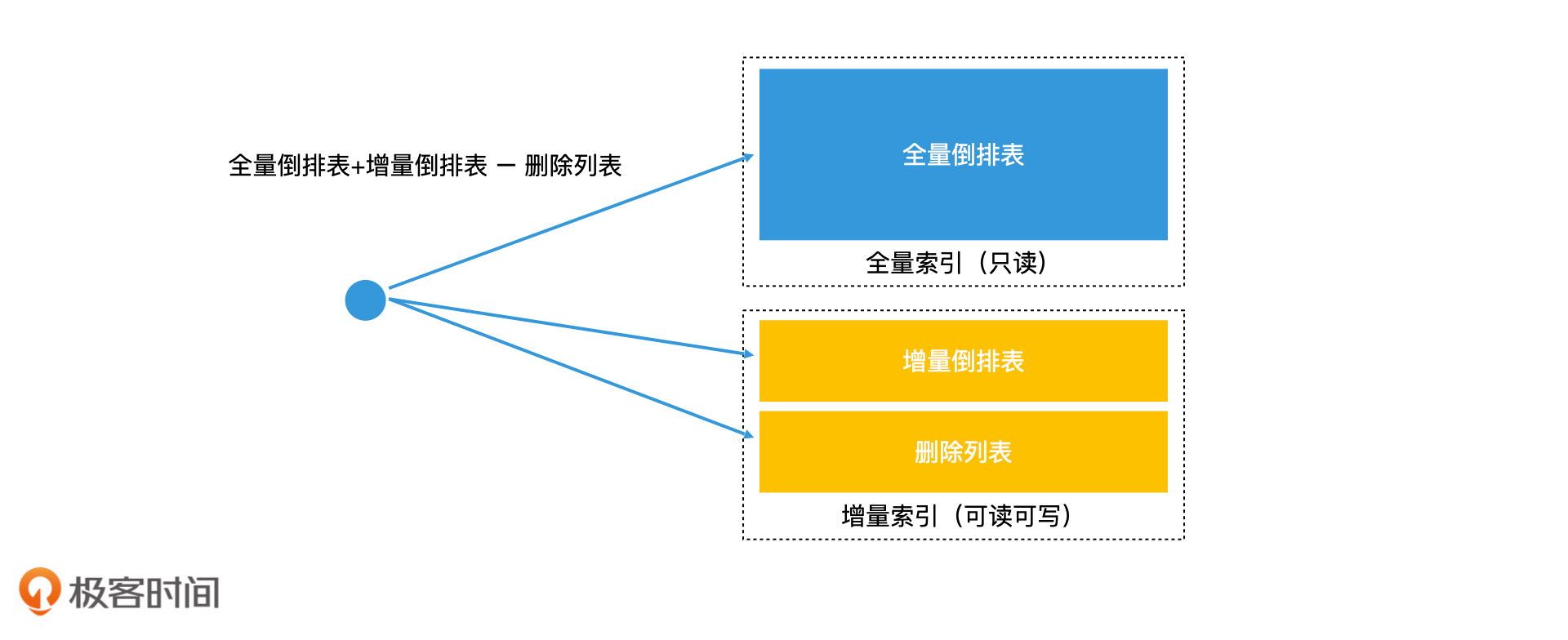
全量索引结合增量索引的检索方案
增量索引空间的持续增长如何处理?
“全量索引结合增量索引”的方案非常实用,但是内存毕竟有限。如果我们不对内存中的增量索引做任何处理,那随着时间推移,内存就会被写满。因此,我们需要在合适的时机将增量索引合并到全量索引中,释放增量索引的内存空间。
将增量索引合并到全量索引中的常见方法有3种,分别是:完全重建法、再合并法和滚动合并法。下面,我们一一来看。
1. 完全重建法
如果增量索引的增长速度不算很快,或者全量索引重建的代价不大,那么我们完全可以在增量索引写满内存空间之前,完全重建一次全量索引,然后将系统查询切换到新的全量索引上。
这样一来,之前旧的增量索引的空间也可以得到释放。这种方案叫作完全重建法。它对于大部分规模不大的检索系统而言,是十分简单可行的方案。
2. 再合并法
尽管完全重建法的流程很简单,但是效率并不是最优的。
在第8讲中我们讲过,对于较大规模的检索系统而言,在构建索引的时候,我们常常会将大数据集分割成多个小数据集,分别建立小索引,再把它们合并成一个大索引。
借助这样的思路,我们完全可以把全量索引想象成是一个已经将多个小索引合并好的大索引,再把增量索引想象成是一个新增的小索引。这样一来,我们完全可以直接归并全量索引和增量索引,生成一个新的全量索引,这也就避免了从头处理所有文档的重复开销。这种方法就是效率更高的再合并法。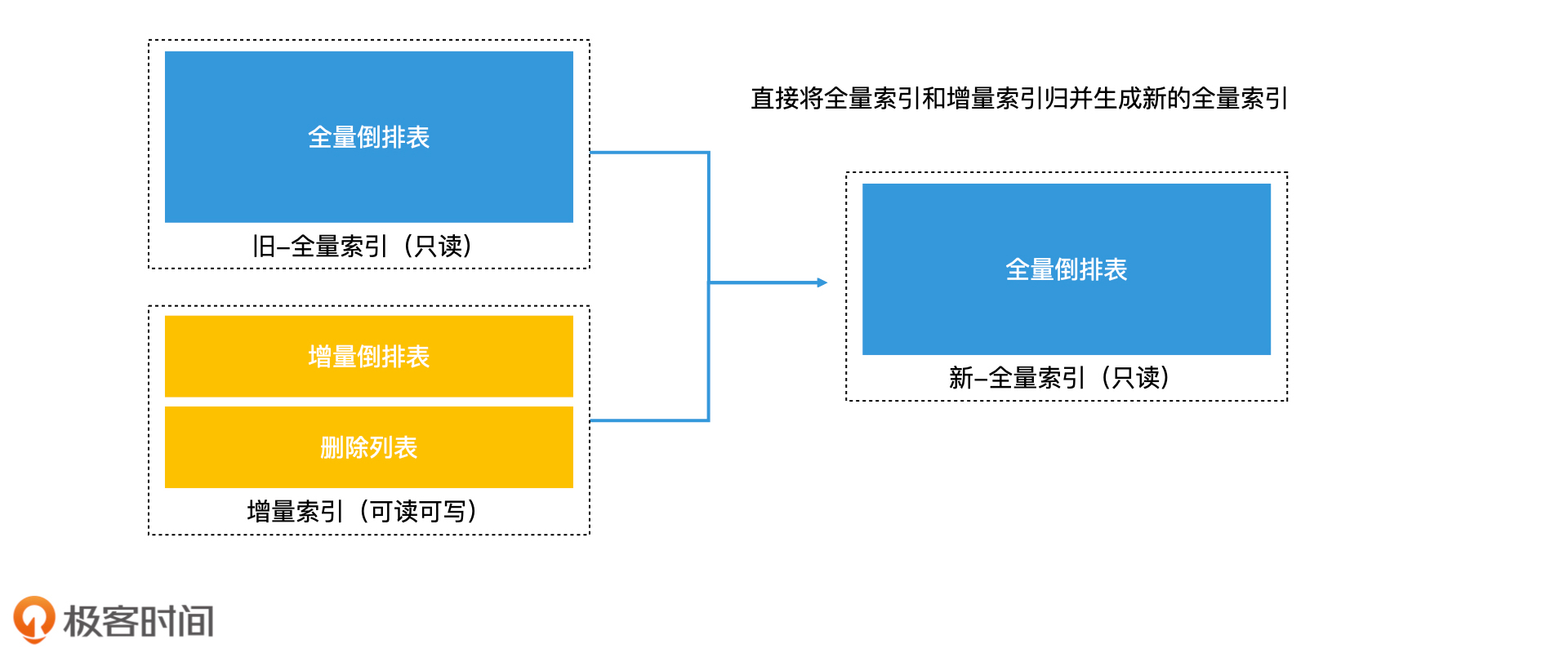
再合并法
3. 滚动合并法
不过,如果全量索引和增量索引的量级差距过大,那么再合并法的效率依然不高。
为什么这么说呢?我们以搜索引擎为例来分析一下。在搜索引擎中,增量索引只有上万条记录,但全量索引可能有万亿条记录。这样的两个倒排索引合并的过程中,只有少数词典中的关键词和文档列表会被修改,其他大量的关键词和文档列表都会从旧的全量索引中被原样复制出来,再重写入到新的全量索引中,这会带来非常大的无谓的磁盘读写开销。因此,对于这种量级差距过大的全量索引和增量索引的归并来说,如何避免无谓的数据复制就是一个核心问题。
最直接的解决思路就是原地更新法。所谓“原地更新法”,就是不生成新的全量索引,直接在旧的全量索引上修改。
但这种方法在工程实现上其实效率并不高,原因有两点。
首先,它要求倒排文件要拆散成多个小文件,每个关键词对应的文档列表为一个小文件,这样才可以将增量索引中对应的变化直接在对应的小文件上单独修改。但这种超大规模量级的零散小文件的高效读写,许多操作系统是很难支持的。
其次,由于只有一份全量索引同时支持读和写,那我们就需要“加锁”,这肯定也会影响检索效率。因此,在一些大规模工程中,我们并不会使用原地更新法。
这就又回到了我们前面要解决的核心问题,也就是如何避免无谓的数据复制,那在工业界中常用的减少无谓数据复制的方法就是滚动合并法。所谓滚动合并法,就是先生成多个不同层级的索引,然后逐层合并。
比如说,一个检索系统在磁盘中保存了全量索引、周级索引和天级索引。所谓周级索引,就是根据本周的新数据生成的一份索引,那天级索引就是根据每天的新数据生成的一份索引。在滚动合并法中,当内存中的增量索引增长到一定体量时,我们会用再合并法将它合并到磁盘上当天的天级索引文件中。
由于天级的索引文件条数远远没有全量索引多,因此这不会造成大量的无谓数据复制。等系统中积累了7天的天级索引文件后,我们就可以将这7个天级索引文件合并成一个新的周级索引文件。因此,在每次合并增量索引和全量索引的时候,通过这样逐层滚动合并的方式,就不会进行大量的无谓数据复制的开销。这个过程就叫作滚动合并法。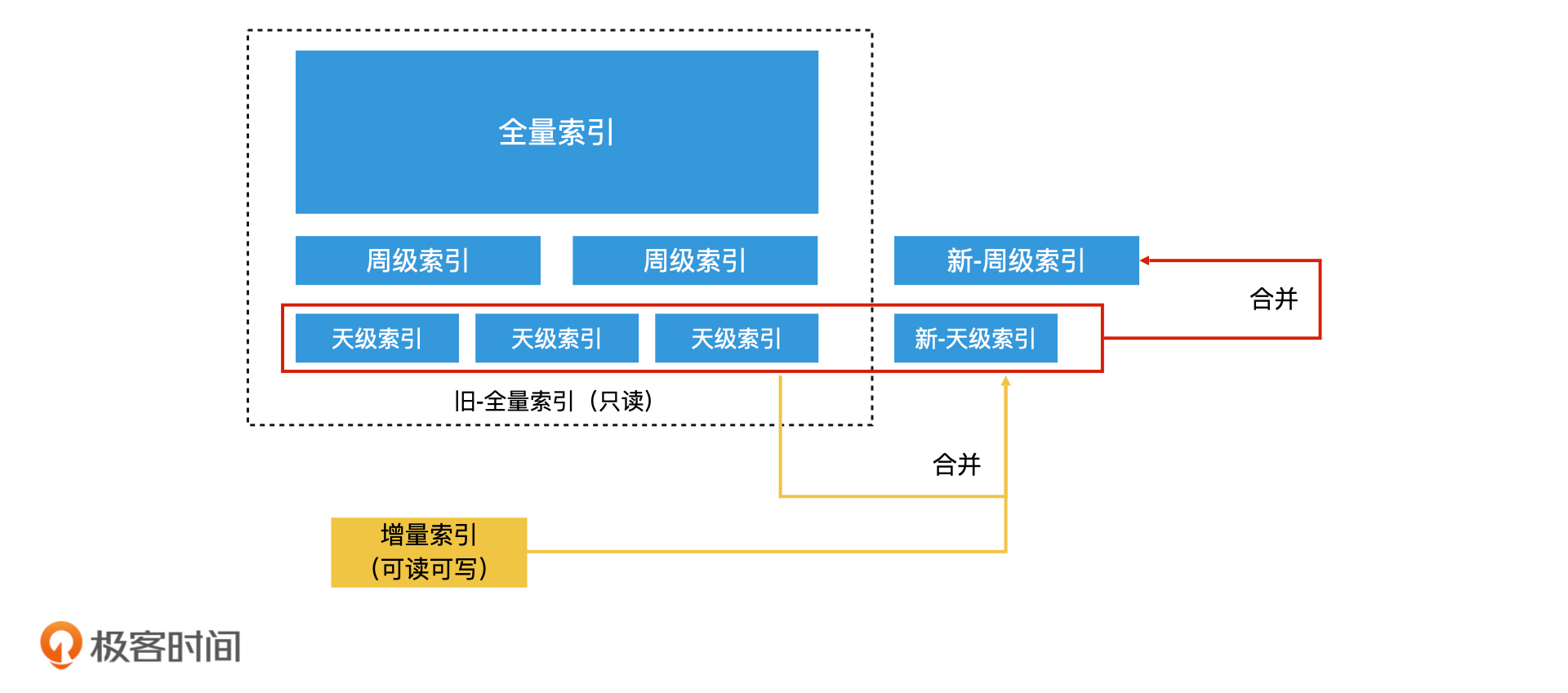
滚动合并法
重点回顾
今天,我们介绍了工业界中,不同规模的倒排索引对应的索引更新方法。
对于内存资源足够的小规模索引,我们可以直接使用Double Buffer机制更新内存中的索引;对于内存资源紧张的大规模索引,我们可以使用“全量索引结合增量索引”的方案来更新内存中的索引。
在“全量索引结合增量索引”的方案中,全量索引根据内存资源的使用情况不同,它既可以存在内存中,也可以存在磁盘上。而增量索引则需要全部存在内存中。
当增量索引增长到上限时,我们需要合并增量索引和全量索引,根据索引的规模和增长速度,我们可以使用的合并方法有完全重建法、再合并法和滚动合并法。
除此之外,我们还讲了一个很重要的工业设计思想,就是读写分离。实际上,高效的索引更新方案都应用了读写分离的思想,将主要的数据检索放在一个只读的组件上。这样,检索时就不会有读写同时发生的竞争状态了,也就避免了加锁。事实上,无论是Double Buffer机制,还是全量索引结合增量索引,都是读写分离的典型例子。
课堂讨论
为什么在增量索引的方案中,对于删除的数据,我们不是像LSM树一样在索引中直接做删除标记,而是额外增加一个删除列表?
欢迎在留言区畅所欲言,说出你的思考过程。如果有收获,也欢迎把这篇文章分享给你的朋友。