05 | 倒排索引:如何从海量数据中查询同时带有“极”和“客”的唐诗?
你好,我是陈东。
试想这样一个场景:假设你已经熟读唐诗300首了。这个时候,如果我给你一首诗的题目,你可以马上背出这首诗的内容吗?相信你一定可以的。但是如果我问你,有哪些诗中同时包含了“极”字和“客”字?你就不见得能立刻回答出来了。你需要在头脑中一首诗一首诗地回忆,并判断每一首诗的内容是否同时包含了“极”字和“客”字。很显然,第二个问题的难度比第一个问题大得多。
那从程序设计的角度来看,这两个问题对应的检索过程又有什么不同呢?今天,我们就一起来聊一聊,两个非常常见又非常重要的检索技术:正排索引和倒排索引。
什么是倒排索引?
我们先来看比较简单的那个问题:给出一首诗的题目,马上背出内容。这其实就是一个典型的键值查询场景。针对这个场景,我们可以给每首诗一个唯一的编号作为ID,然后使用哈希表将诗的ID作为键(Key),把诗的内容作为键对应的值(Value)。这样,我们就能在O(1)的时间代价内,完成对指定key的检索。这样一个以对象的唯一ID为key的哈希索引结构,叫作正排索引(Forward Index)。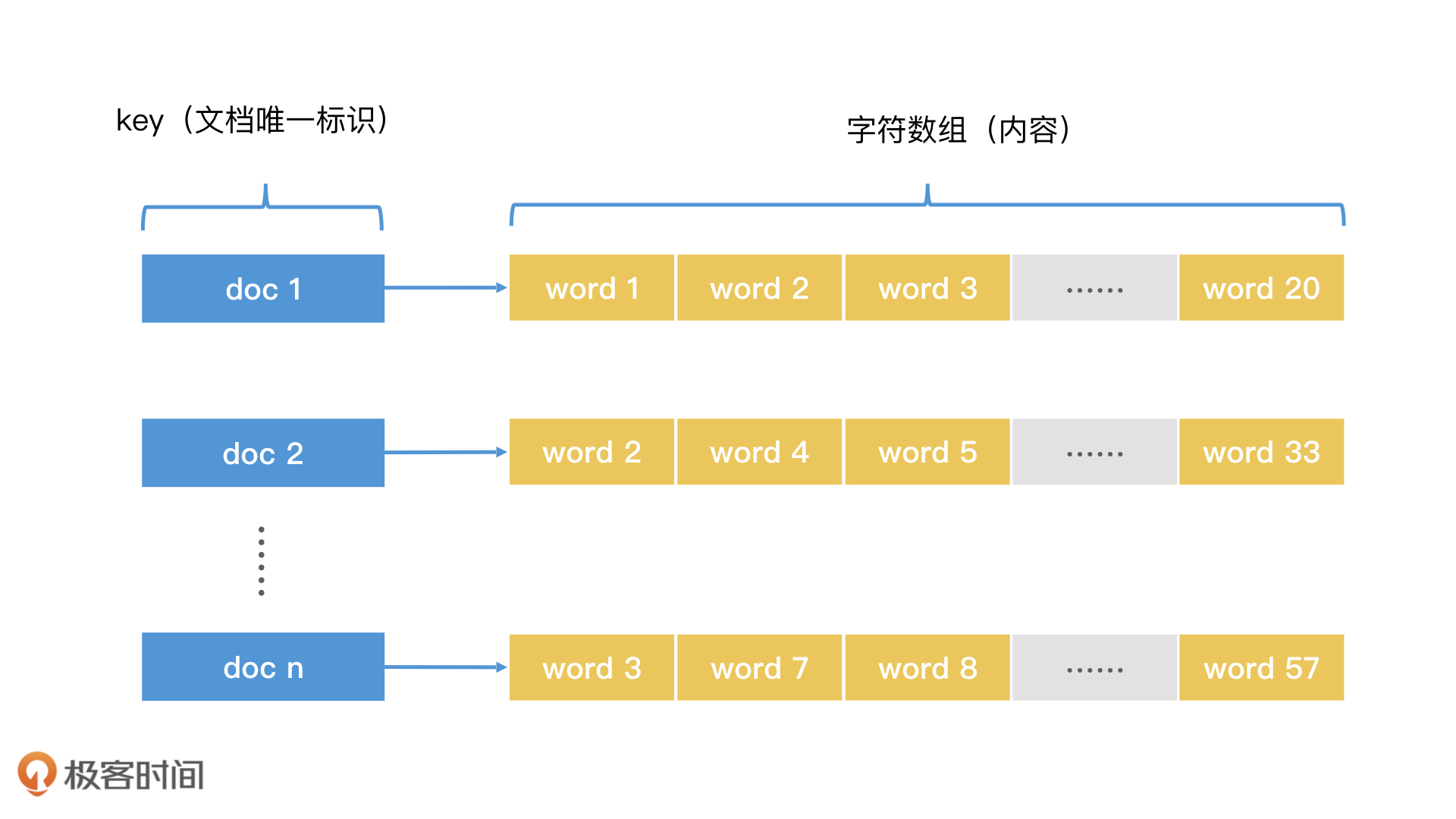
哈希表存储所有诗
一般来说,我们会遍历哈希表,遍历的时间代价是O(n)。在遍历过程中,对于遇到的每一个元素也就是每一首诗,我们需要遍历这首诗中的每一个字符,才能判断是否包含“极”字和“客”字。假设每首诗的平均长度是k,那遍历一首诗的时间代价就是O(k)。从这个分析中我们可以发现,这个检索过程全部都是遍历,因此时间代价非常高。对此,有什么优化方法吗?
我们先来分析一下这两个场景。我们会发现,“根据题目查找内容”和“根据关键字查找题目”,这两个问题其实是完全相反的。既然完全相反,那我们能否“反着”建立一个哈希表来帮助我们查找呢?也就是说,如果我们以关键字作为key建立哈希表,是不是问题就解决了呢?接下来,我们就试着操作一下。
我们将每个关键字当作key,将包含了这个关键字的诗的列表当作存储的内容。这样,我们就建立了一个哈希表,根据关键字来查询这个哈希表,在O(1)的时间内,我们就能得到包含该关键字的文档列表。这种根据具体内容或属性反过来索引文档标题的结构,我们就叫它倒排索引(Inverted Index)。在倒排索引中,key的集合叫作字典(Dictionary),一个key后面对应的记录集合叫作记录列表(Posting List)。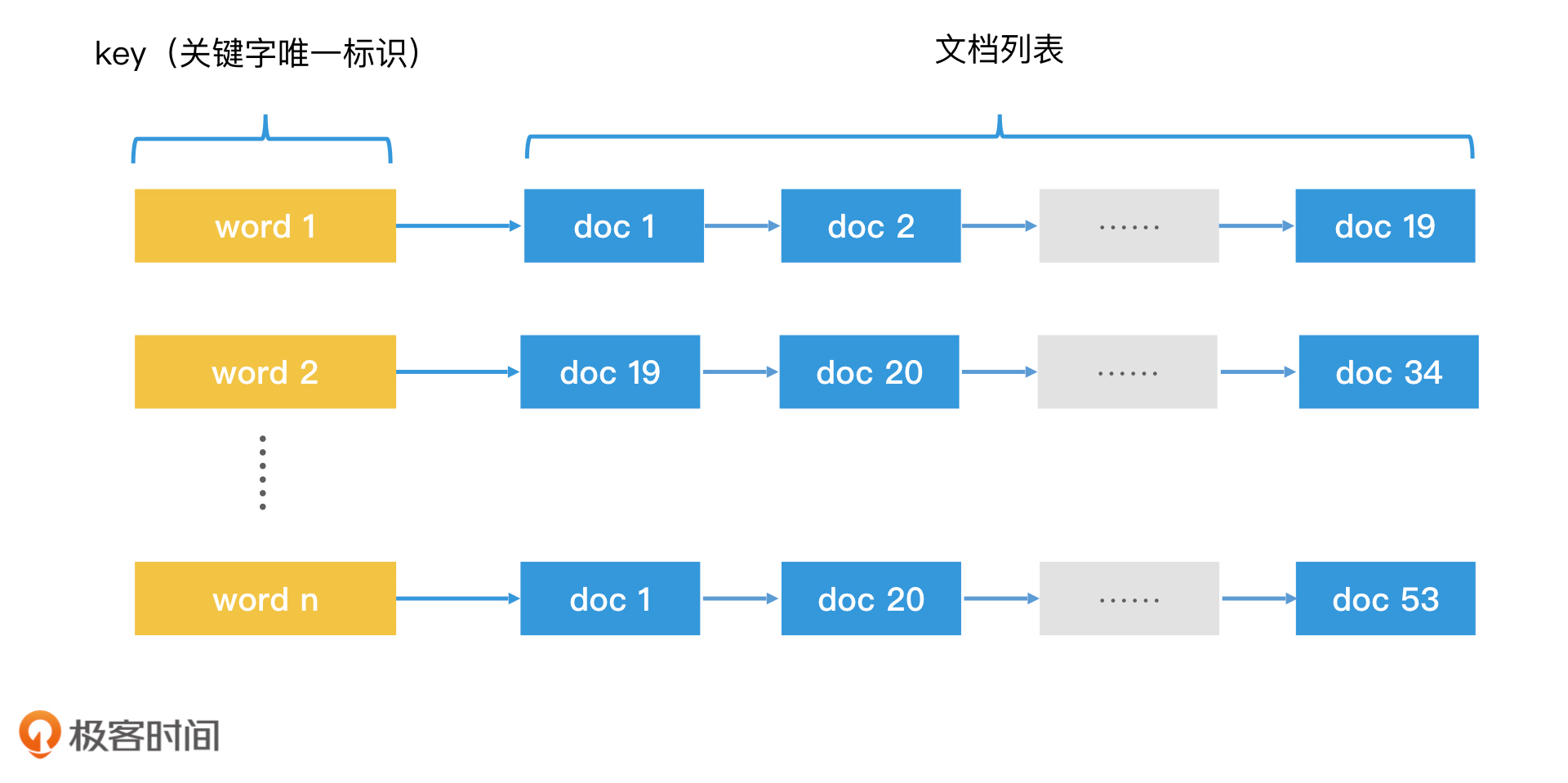
倒排索引
如何创建倒排索索引?
前面我们介绍了倒排索引的概念,那创建一个倒排索引的过程究竟是怎样的呢?我把这个过程总结成了以下步骤。
- 给每个文档编号,作为其唯一的标识,并且排好序,然后开始遍历文档(为什么要先排序,然后再遍历文档呢?你可以先想一下,后面我们会解释)。
- 解析当前文档中的每个关键字,生成<关键字,文档ID,关键字位置>这样的数据对。为什么要记录关键字位置这个信息呢?因为在许多检索场景中,都需要显示关键字前后的内容,比如,在组合查询时,我们要判断多个关键字之间是否足够近。所以我们需要记录位置信息,以方便提取相应关键字的位置。
- 将关键字作为key插入哈希表。如果哈希表中已经有这个key了,我们就在对应的posting list后面追加节点,记录该文档ID(关键字的位置信息如果需要,也可以一并记录在节点中);如果哈希表中还没有这个key,我们就直接插入该key,并创建posting list和对应节点。
- 重复第2步和第3步,处理完所有文档,完成倒排索引的创建。
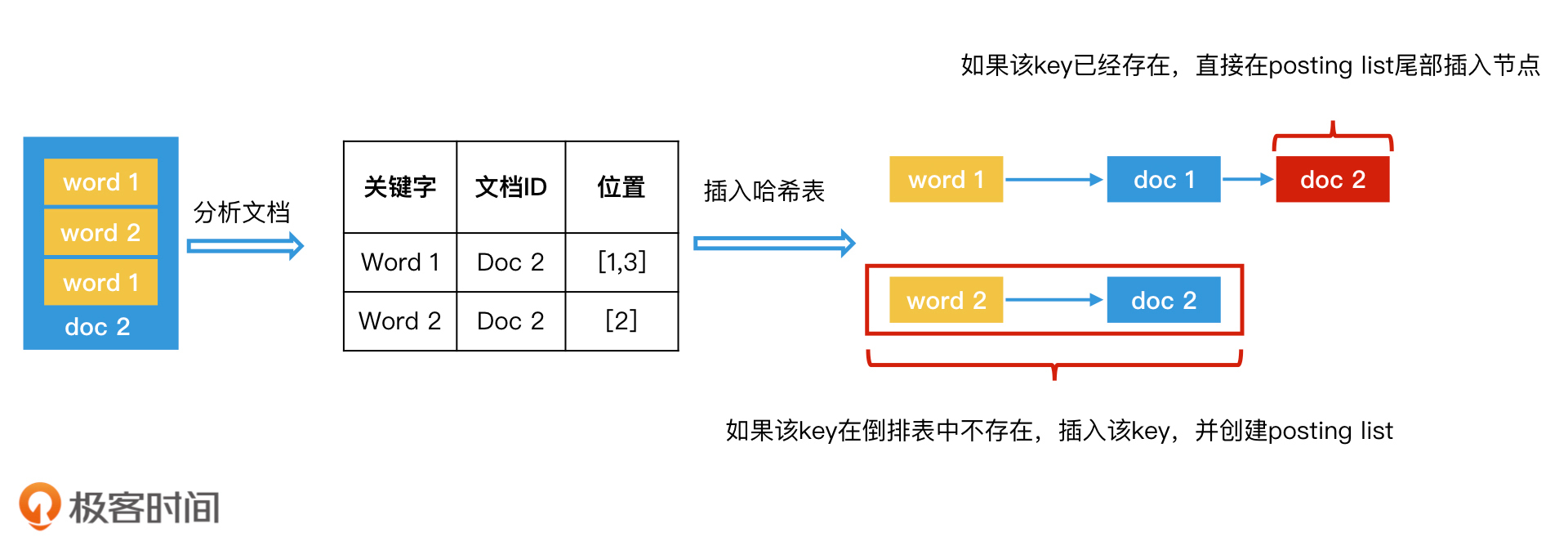
将一个文档解析并加入倒排索引
如何查询同时含有“极”字和“客”字两个key的文档?
如果只是查询包含“极”或者“客”这样单个字的文档,我们直接以查询的字作为key去倒排索引表中检索,得到的posting list就是结果了。但是,如果我们的目的是要查询同时包含“极”和“客”这两个字的文档,那我们该如何操作呢?
我们可以先分别用两个key去倒排索引中检索,这样会得到两个不同的posting list:A和B。A中的文档都包含了“极”字,B中文档都包含了“客”字。那么,如果一个文档既出现在A中,又出现在B中,它是不是就同时包含了这两个字呢?按照这个思路,我们只需查找出A和B的公共元素即可。
那么问题来了,我们该如何在A和B这两个链表中查找出公共元素呢?如果A和B都是无序链表,那我们只能将A链表和B链表中的每个元素分别比对一次,这个时间代价是O(m*n)。但是,如果两个链表都是有序的,我们就可以用归并排序的方法来遍历A和B两个链表,时间代价会降低为O(m + n),其中m是链表A的长度,n是链表B的长度。
我把链表归并的过程总结成了3个步骤,你可以看一看。
第1步,使用指针p1和p2分别指向有序链表A和B的第一个元素。
第2步,对比p1和p2指向的节点是否相同,这时会出现3种情况:
- 两者的id相同,说明该节点为公共元素,直接将该节点加入归并结果。然后,p1和p2要同时后移,指向下一个元素;
- p1元素的id小于p2元素的id,p1后移,指向A链表中下一个元素;
- p1元素的id大于p2元素的id,p2后移,指向B链表中下一个元素。
第3步,重复第2步,直到p1或p2移动到链表尾为止。
为了帮助你理解,我把一个链表归并的完整例子画在了一张图中,你可以结合这张图进一步理解上面的3个步骤。
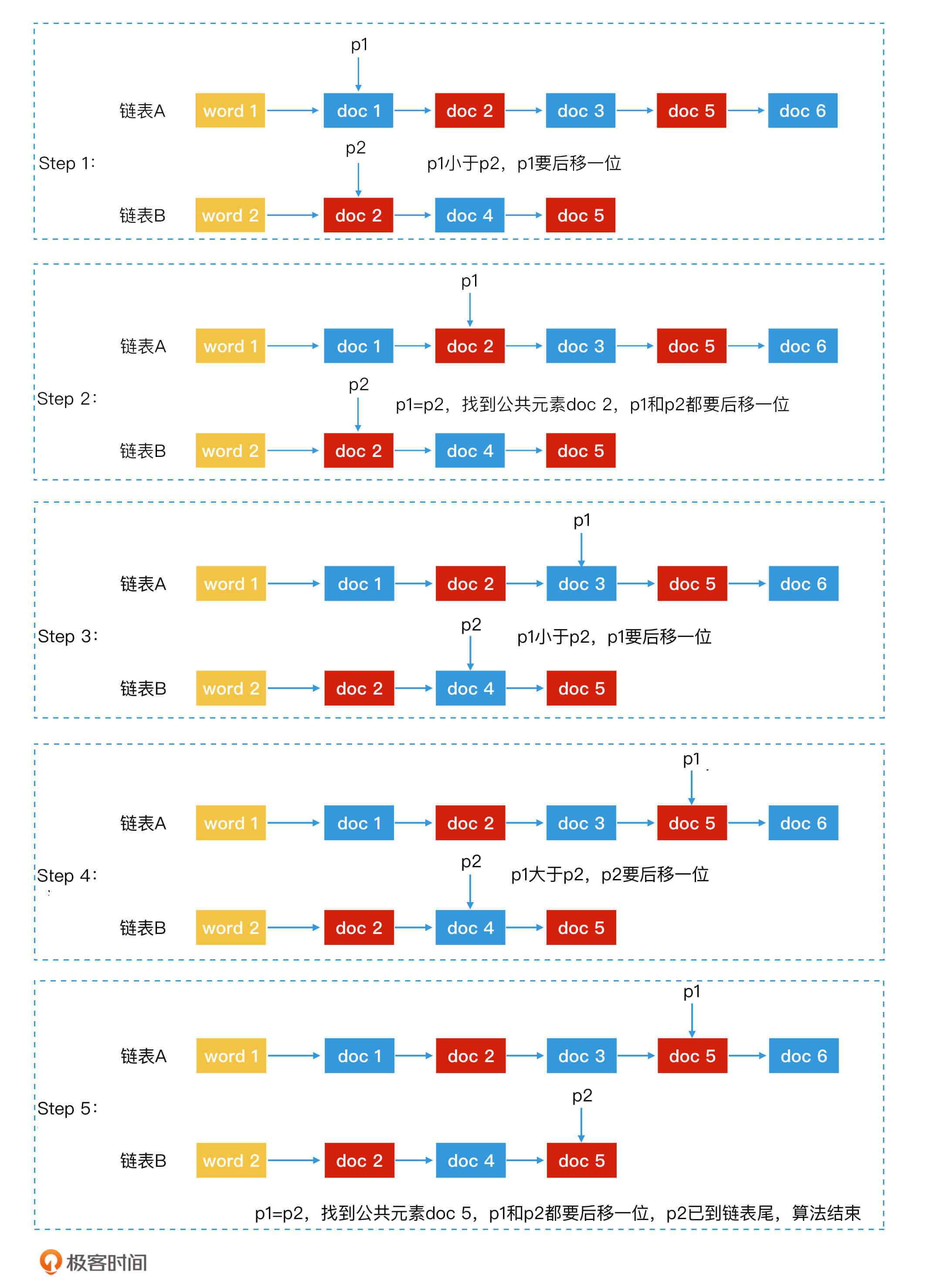
链表归并提取公共元素例子
那对于两个key的联合查询来说,除了有“同时存在”这样的场景以外,其实还有很多联合查询的实际例子。比如说,我们可以查询包含“极”或“客”字的诗,也可以查询包含“极”且不包含“客”的诗。这些场景分别对应着集合合并中的交集、并集和差集问题。它们的具体实现方法和“同时存在”的实现方法差不多,也是通过遍历链表对比的方式来完成的。如果感兴趣的话,你可以自己来实现看看,这里我就不再多做阐述了。
此外,在实际应用中,我们可能还需要对多个key进行联合查询。比如说,要查询同时包含“极”“客”“时”“间”四个字的诗。这个时候,我们利用多路归并的方法,同时遍历这四个关键词对应的posting list即可。实现过程如下图所示。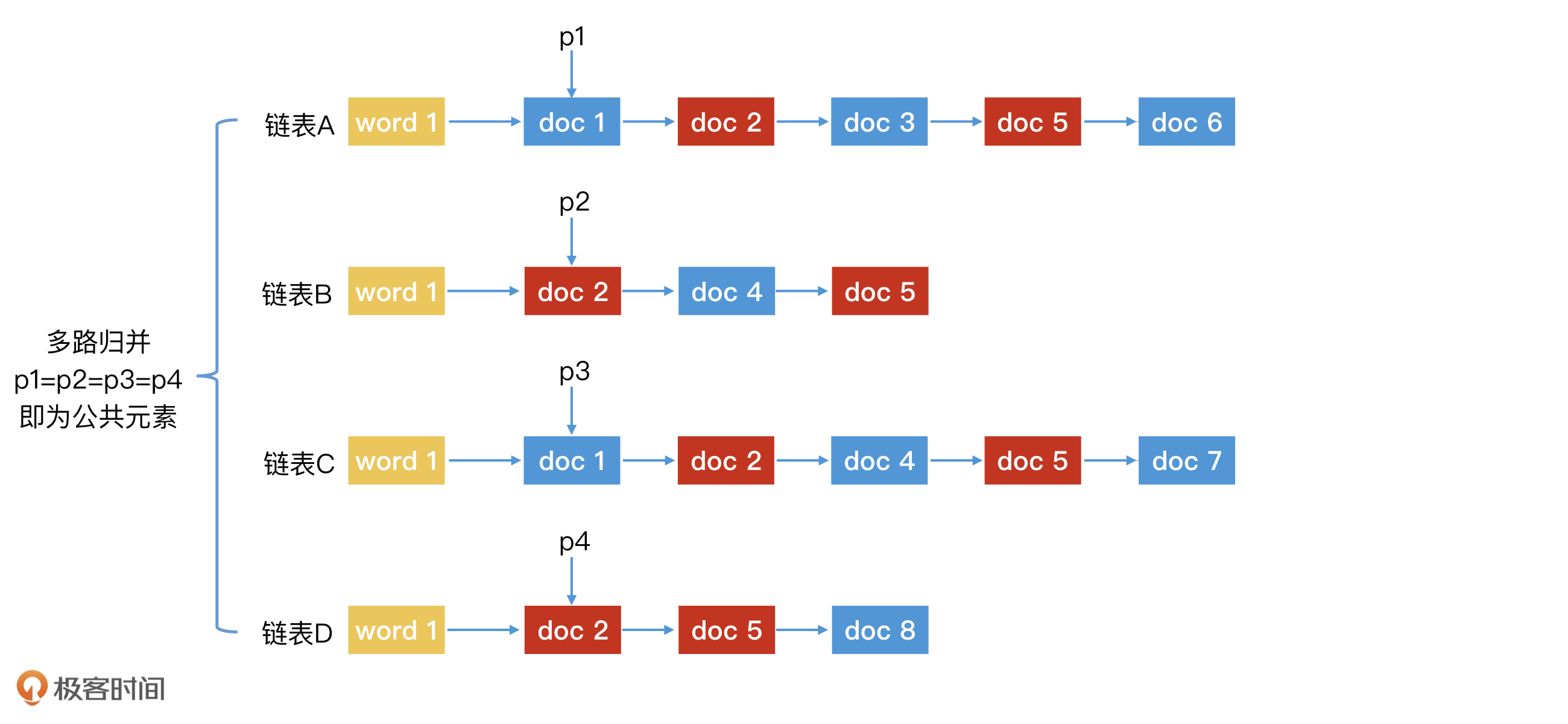
多路归并
重点回顾
好了,今天的内容就先讲到这里。你会发现,倒排索引的核心其实并不复杂,它的具体实现其实是哈希表,只是它不是将文档ID或者题目作为key,而是反过来,通过将内容或者属性作为key来存储对应的文档列表,使得我们能在O(1)的时间代价内完成查询。
尽管原理并不复杂,但是倒排索引是许多检索引擎的核心。比如说,数据库的全文索引功能、搜索引擎的索引、广告引擎和推荐引擎,都使用了倒排索引技术来实现检索功能。因此,这一讲的内容我也希望你能好好理解消化,打好扎实的基础。
课堂讨论
今天的内容实践性比较强,你可以结合下面这道课堂讨论题,动手试一试,加深理解。
对于一个检索系统而言,除了根据关键字查询文档,还可能有其他的查询需求。比如说,我们希望查询李白都写了哪些诗。也就是说,如何在“根据内容查询”的基础上,同时支持“根据作者查询”,我们该怎么做呢?
欢迎在留言区畅所欲言,说出你的思考过程和最终答案。如果有收获,也欢迎把这篇文章分享给你的朋友。