02 | 分离关注点:软件设计至关重要的第一步
你好!我是郑晔。
上一讲我们讲了软件开发就是在解决问题。那问题一般是如何解决的呢?最常见的解决问题思路是分而治之,也就是说,我们要先把问题拆分开。在每个问题都得到解决之后,再把这些解决好的子问题以恰当的方式组装起来。如何分解与组合,就是我们要在软件设计中考虑的问题。
然而,在软件设计这个环节中,大部分人都把焦点放在了如何组合上,却忽略了至关重要的第一步:分解。你可能会觉得:“分解?我会啊,不就是把一个大系统拆成若干个子系统,再把子系统再拆成若干个模块,一层一层拆下去嘛。”
然而,在我看来,这种程度的分解远远不够,因为分解出来的粒度太大了。粒度太大会造成什么影响呢?这会导致我们把不同的东西混淆在一起,为日后埋下许多隐患。
为什么这么说呢?我来给你举个例子。
一个失败的分解案例
我曾经见过一个故障频出的清结算系统,它的主要职责是执行清结算。一开始我觉得,清结算系统是一个业务规则比较多的系统,偶尔出点故障,也是情有可原。
但是在分析了这个系统的故障报告后,我们发现这个系统设计得极其复杂。其中有一处是这样的:上游系统以推送的方式向这个系统发消息。在原本的实现中,开发人员发现这个过程可能会丢消息,于是,他们设计了一个补偿机制。
因为推送过来的数据是之前由这个系统发出去的,它本身有这些数据的初始信息,于是,开发人员就在数据库里增加了一个状态,记录消息返回的情况。一旦发现丢消息了,这个系统就会访问上游系统的接口,将丢失的数据请求回来。
正是这个补偿机制的设计,带来了一系列的后续问题。比如,当系统业务量增加的时候,数据库访问的压力本身就很大,但在这种场景下,丢数据的概率也增加了,用于补偿的线程也会频繁访问数据库,因为它要找出丢失的数据,还要把请求回来的数据写回到数据库里。
也就是说,一旦业务量上升,本来就已经很吃力的系统,它的负担就更重了,系统出现卡顿也就在所难免了。
这个补偿机制的设计是有问题的,问题的点在于,上游系统向下游推送消息,这应该是一个通信层面的问题。而在原有的设计中,因为那个状态的添加,这个问题被带到了业务层面。
这就是一个典型的分解没有做好的例子,是分解粒度太大造成的。开发人员只考虑了业务功能,忽视其他维度。技术和业务被混在了一起,随之而来的就是无尽的后患。
一旦理解了这一点,我们就可以想办法解决了。既然是否丢消息是通信层面的事,我们就争取在通信层面解决它。我们当时的解决方案是,选择了一个吞吐量更大的消息队列。在未来可见的业务量下,消息都不会丢。通信层面的问题在通信层面解决了,业务层面也就不会受到影响了。果不其然,这样改造之后,系统的稳定性得到了大幅度的提升。
上面我只讲了这个故事的主线,其实,相关的事情还有一些。比如,上游系统专门为补偿而开发的接口,现在也不需要了,于是上游系统得到了简化;这个系统里那个表示状态的字段,其实还被用在了业务处理中,也引发过其他问题,现在它只用在业务处理中,角色单一了,与此相关的问题也少了。
分离关注点
至此,我们已经对分解粒度太大所造成的影响,有了一个初步的了解。那在做设计时,该如何考虑分解呢?传统上,我们习惯的分解问题的方式是树型的。比如,按功能分解,可分为:功能1、功能2、功能3,等等,然后,每个功能再分成功能1.1、功能1.2、功能2.1、功能3.1等等,以此类推。
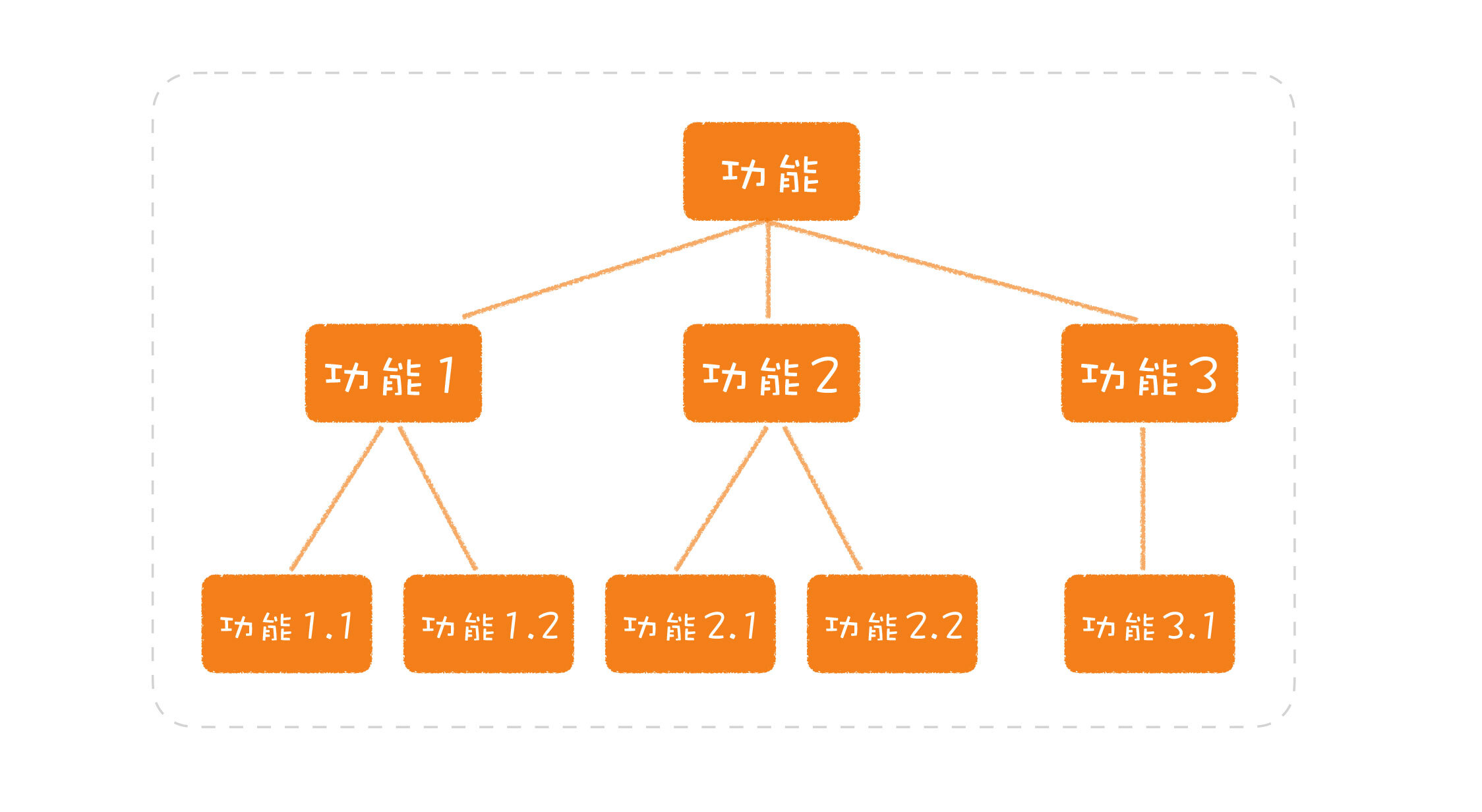
如果只从业务上看,这似乎没什么问题。但我们要实现一个真实的系统,就不仅仅要考虑功能性的需求,还要考虑非功能性的需求。比如,前面提到的数据不能丢失、有的系统还要求处理速度要快,等等。
这与业务并不是一个维度的事情,我们在做设计时,要能够发现这些非功能性的需求。也就是说,我们在分解问题的时候,会有很多维度,每一个维度都代表着一个关注点,这就是设计中一个常见的说法,“分离关注点(Separation of concerns)”。
可以分离的关注点有非常多,你只要稍微注意一下,就能识别出来。但还有一些你可能注意不到,结果导致了混淆。最常见的一类问题就是把业务处理和技术实现两个关注点混在了一起,前面举的那个例子就是一个典型。
对于“把业务处理和技术实现混在一起”的问题,我再给你举个例子。如果现在业务的处理性能跟不上,你有什么办法解决吗?大多数程序员的第一反应是,多线程啊!
没错,多线程的确是一种解决办法。但如果不加限制地让人去把这段代码改成多线程的,一些多线程相关的问题也会随之而来。比如,让人头疼的资源竞争、数据同步等等。
写好业务规则和正确地处理多线程,这是两个不同的关注点。如果我们把二者放到同一段代码里去写,彼此影响也就在所难免了。问题说明白了,解决方案才能清楚,那就是把业务处理和多线程处理的代码分开。
按照我的理解,大部分程序员都不应该编写多线程程序。由专门的程序员把并发处理的部分封装成框架,大家在里面写业务代码就好了。
把业务处理和技术实现混在一起,类似问题还有很多。比如我们经常问怎么处理分布式事务,怎么做分库分表等。其实,你更应该问的是,我的业务需要分布式事务吗?我是不是业务划分没有做清楚,才造成了数据库的压力?
在真实项目中,程序员最常犯的错误就是认为所有问题都是技术问题,总是试图用技术解决所有问题。任何试图用技术去解决其他关注点的问题,只能是陷入焦油坑之中,越挣扎,陷得越深。
另外一个常见的容易产生混淆的关注点是不同的数据变动方向。
有人问过我这样一个问题:在Java应用里,做数据库访问用Spring Data JPA好,还是MyBatis好。Spring Data JPA简化了数据库访问,自动生成对应的SQL语句,而MyBatis则要自己手写SQL。
普通的增删改查用Spring Data JPA非常省事,但对于一些复杂场景,他会担心自动生成SQL的性能有问题,还是手写SQL优化来得直接。是不是挺纠结的?
随即我又问了他一个问题,为什么需要复杂查询呢?他告诉我,有一些统计报表需要。
不知道你是否发现了其中混淆关注点的地方?普通的增删改查需要经常改动数据库,而复杂查询的使用频率其实是很低的。
从本质上说,之所以出现工具选择的困难,是因为他把两种数据使用频率不同的场景混在一起所造成的。如果将前台访问(处理增删改查)和后台访问(统计报表)分开,纠结也就不复存在了。
不同的数据变动方向还有很多,比如:
- 动静分离,就是把变和不变的内容分开;
- 读写分离,就是把读和写分开;
- 前面提到的高频和低频,也可以分解开;
- ……
不同的数据变动方向,就是一个潜在的、可以分离的关注点。
在实际的项目中,可以分离的关注点远不止这些。做设计时,你需要一直有一根弦去发现不同的关注点。分离关注点,不只适用于宏观的层面。
在微观的代码层面,你用同样的思维方式,也可以帮助你识别出一些混在一起的代码。比如,很多程序员很喜欢写setter,但你真的有那么多要改变的东西吗?实际上可能就是封装没做好而已。
分离关注点之所以重要,有两方面原因。一方面,不同的关注点混在一起会带来一系列的问题,正如前面提到的各种问题;另一方面,当分解得足够细小,你就会发现不同模块的共性,才有机会把同样的信息聚合在一起。这会为软件设计的后续过程,也就是组合,做好准备。
总结时刻
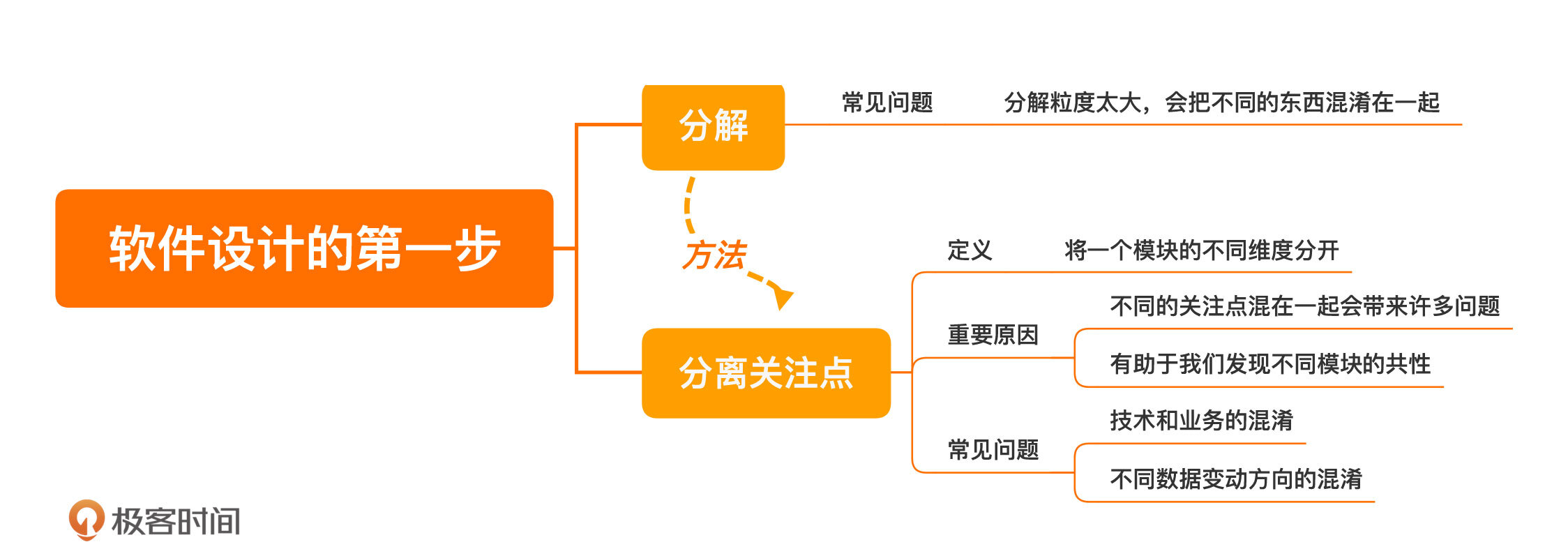
今天,我们学习了软件设计中至关重要的第一步:分解。
大多数系统的设计做得不够好,问题常常出现在分解这步就没做好。常见的分解问题就是分解的粒度太大,把各种维度混淆在一起。在设计中,将一个模块的不同维度分开,有一个专门的说法,叫分离关注点。
分离关注点很重要,一方面,不同的关注点混在一起会带来许多问题;另一方面,分离关注点有助于我们发现不同模块的共性,更好地进行设计。分离关注点,是我们在做设计的时候,需要时时绷起的一根弦。
今天,我还给你举了两种常见的关注点混淆的情况。一种是技术和业务的混淆,另一种是不同数据变动方向的混淆。希望你在日常开发中,引以为戒。
好,我们已经迈出了软件设计的第一步。接下来,就该考虑如何组合了。在组合的过程中,会有很多因素影响到组合的方式。下一讲我们就来看一个非常重要却不受重视的因素:可测试性。
如果今天的内容你只能记住一件事,那请记住:分离关注点,发现的关注点越多越好,粒度越小越好。
思考题
最后我想请你去了解一下CQRS(Command Query Responsibility Segregation),看看它分离了哪些关注点,以及在什么样的场景下使用这种架构是合理的。欢迎在留言区写下你的想法。
感谢阅读,如果你觉得这一讲的内容对你有帮助的话,也欢迎把它分享给你的朋友。