33 | 自己动手写高性能HTTP服务器(二):I/O模型和多线程模型实现
你好,我是盛延敏,这里是网络编程实战第33讲,欢迎回来。
这一讲,我们延续第32讲的话题,继续解析高性能网络编程框架的I/O模型和多线程模型设计部分。
多线程设计的几个考虑
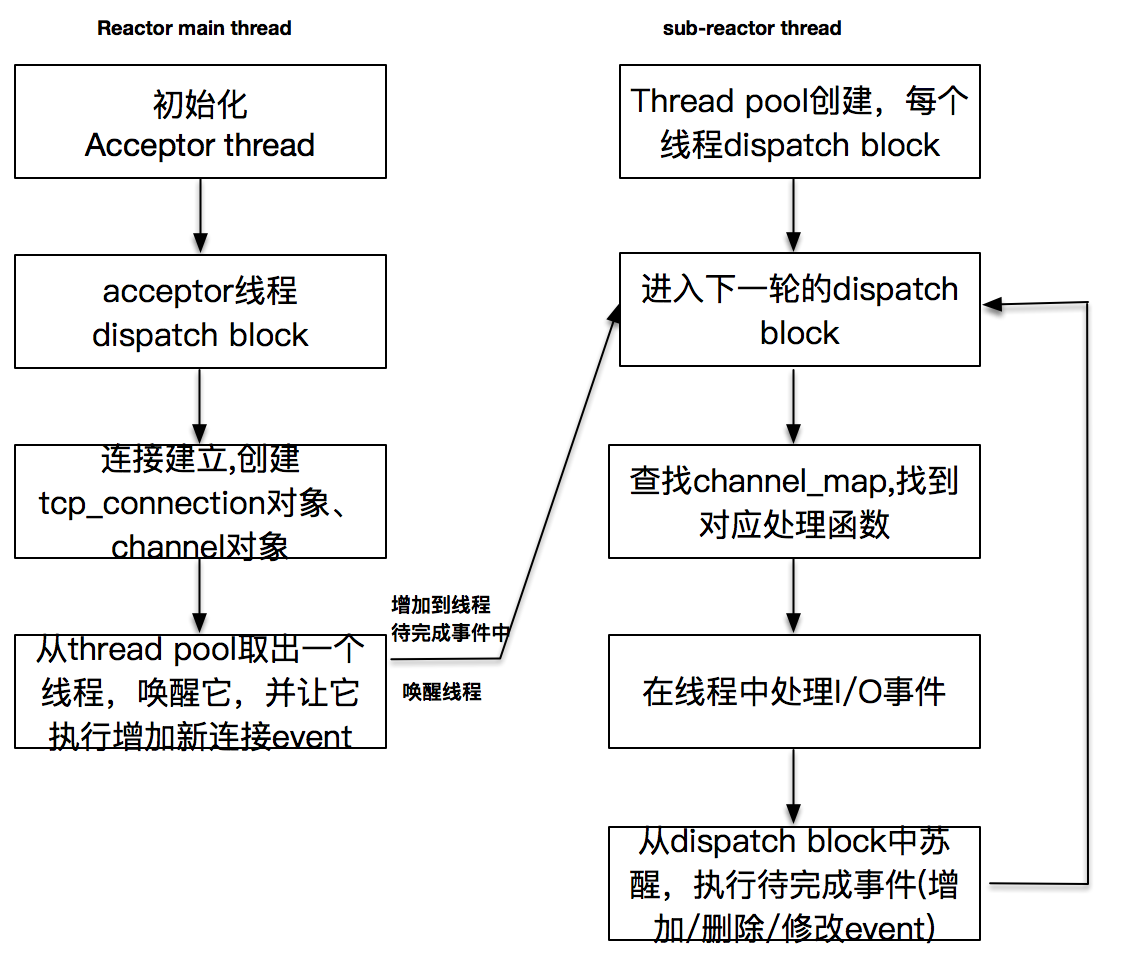
在我们的设计中,main reactor线程是一个acceptor线程,这个线程一旦创建,会以event_loop形式阻塞在event_dispatcher的dispatch方法上,实际上,它在等待监听套接字上的事件发生,也就是已完成的连接,一旦有连接完成,就会创建出连接对象tcp_connection,以及channel对象等。
当用户期望使用多个sub-reactor子线程时,主线程会创建多个子线程,每个子线程在创建之后,按照主线程指定的启动函数立即运行,并进行初始化。随之而来的问题是,主线程如何判断子线程已经完成初始化并启动,继续执行下去呢?这是一个需要解决的重点问题。
在设置了多个线程的情况下,需要将新创建的已连接套接字对应的读写事件交给一个sub-reactor线程处理。所以,这里从thread_pool中取出一个线程,通知这个线程有新的事件加入。而这个线程很可能是处于事件分发的阻塞调用之中,如何协调主线程数据写入给子线程,这是另一个需要解决的重点问题。
子线程是一个event_loop线程,它阻塞在dispatch上,一旦有事件发生,它就会查找channel_map,找到对应的处理函数并执行它。之后它就会增加、删除或修改pending事件,再次进入下一轮的dispatch。
这张图阐述了线程的运行关系。
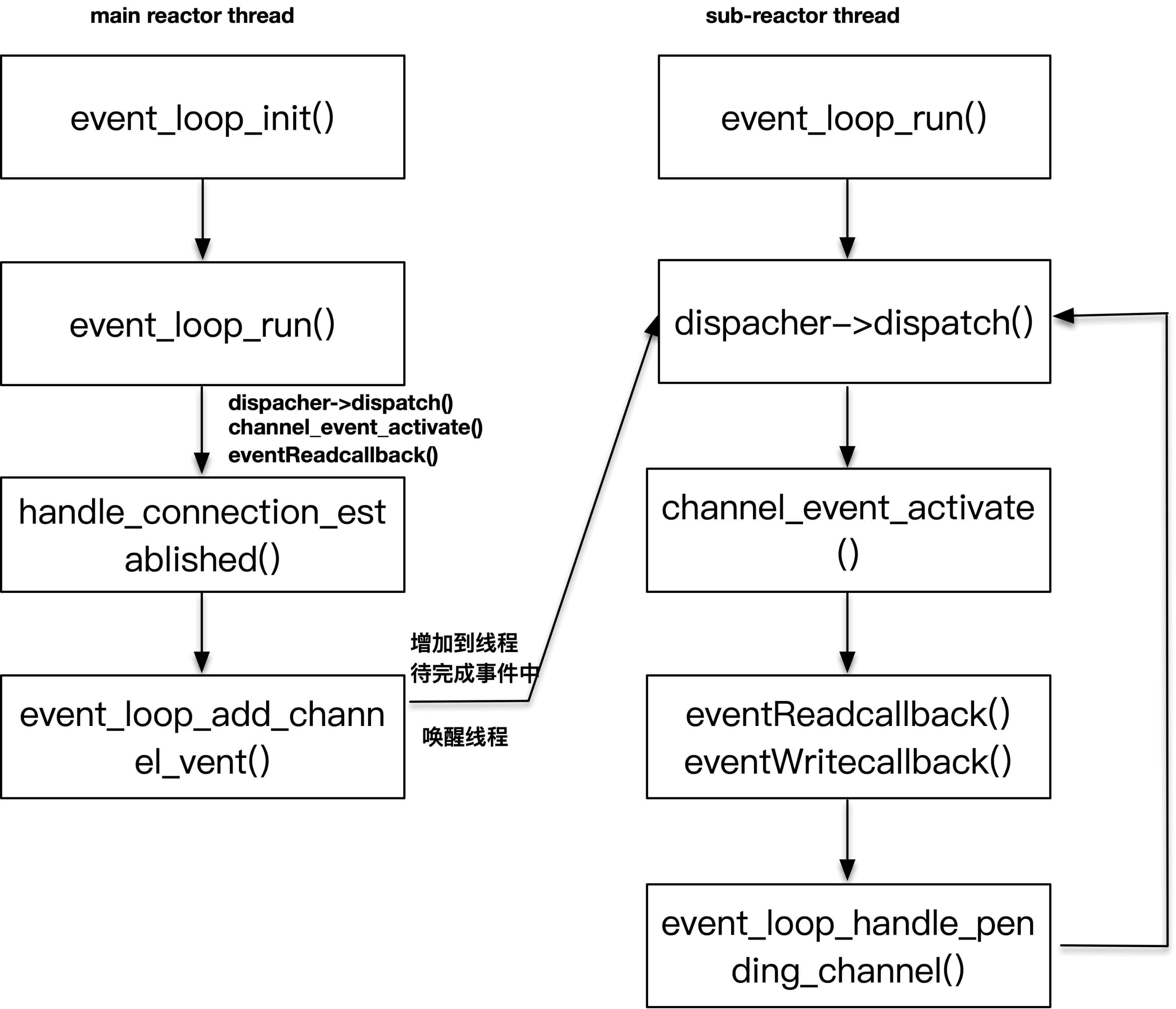
为了方便你理解,我把对应的函数实现列在了另外一张图中。
主线程等待多个sub-reactor子线程初始化完
主线程需要等待子线程完成初始化,也就是需要获取子线程对应数据的反馈,而子线程初始化也是对这部分数据进行初始化,实际上这是一个多线程的通知问题。采用的做法在前面讲多线程的时候也提到过,使用mutex和condition两个主要武器。
下面这段代码是主线程发起的子线程创建,调用event_loop_thread_init对每个子线程初始化,之后调用event_loop_thread_start来启动子线程。注意,如果应用程序指定的线程池大小为0,则直接返回,这样acceptor和I/O事件都会在同一个主线程里处理,就退化为单reactor模式。
//一定是main thread发起void thread_pool_start(struct thread_pool *threadPool) {assert(!threadPool->started);assertInSameThread(threadPool->mainLoop);threadPool->started = 1;void *tmp;if (threadPool->thread_number <= 0) {return;}threadPool->eventLoopThreads = malloc(threadPool->thread_number * sizeof(struct event_loop_thread));for (int i = 0; i < threadPool->thread_number; ++i) {event_loop_thread_init(&threadPool->eventLoopThreads[i], i);event_loop_thread_start(&threadPool->eventLoopThreads[i]);}}
我们再看一下event_loop_thread_start这个方法,这个方法一定是主线程运行的。这里我使用了pthread_create创建了子线程,子线程一旦创建,立即执行event_loop_thread_run,我们稍后将看到,event_loop_thread_run进行了子线程的初始化工作。这个函数最重要的部分是使用了pthread_mutex_lock和pthread_mutex_unlock进行了加锁和解锁,并使用了pthread_cond_wait来守候eventLoopThread中的eventLoop的变量。
//由主线程调用,初始化一个子线程,并且让子线程开始运行event_loopstruct event_loop *event_loop_thread_start(struct event_loop_thread *eventLoopThread) {pthread_create(&eventLoopThread->thread_tid, NULL, &event_loop_thread_run, eventLoopThread);assert(pthread_mutex_lock(&eventLoopThread->mutex) == 0);while (eventLoopThread->eventLoop == NULL) {assert(pthread_cond_wait(&eventLoopThread->cond, &eventLoopThread->mutex) == 0);}assert(pthread_mutex_unlock(&eventLoopThread->mutex) == 0);yolanda_msgx("event loop thread started, %s", eventLoopThread->thread_name);return eventLoopThread->eventLoop;}
为什么要这么做呢?看一下子线程的代码你就会大致明白。子线程执行函数event_loop_thread_run一上来也是进行了加锁,之后初始化event_loop对象,当初始化完成之后,调用了pthread_cond_signal函数来通知此时阻塞在pthread_cond_wait上的主线程。这样,主线程就会从wait中苏醒,代码得以往下执行。子线程本身也通过调用event_loop_run进入了一个无限循环的事件分发执行体中,等待子线程reator上注册过的事件发生。
void *event_loop_thread_run(void *arg) {struct event_loop_thread *eventLoopThread = (struct event_loop_thread *) arg;pthread_mutex_lock(&eventLoopThread->mutex);// 初始化化event loop,之后通知主线程eventLoopThread->eventLoop = event_loop_init();yolanda_msgx("event loop thread init and signal, %s", eventLoopThread->thread_name);pthread_cond_signal(&eventLoopThread->cond);pthread_mutex_unlock(&eventLoopThread->mutex);//子线程event loop runeventLoopThread->eventLoop->thread_name = eventLoopThread->thread_name;event_loop_run(eventLoopThread->eventLoop);}
可以看到,这里主线程和子线程共享的变量正是每个event_loop_thread的eventLoop对象,这个对象在初始化的时候为NULL,只有当子线程完成了初始化,才变成一个非NULL的值,这个变化是子线程完成初始化的标志,也是信号量守护的变量。通过使用锁和信号量,解决了主线程和子线程同步的问题。当子线程完成初始化之后,主线程才会继续往下执行。
struct event_loop_thread {struct event_loop *eventLoop;pthread_t thread_tid; /* thread ID */pthread_mutex_t mutex;pthread_cond_t cond;char * thread_name;long thread_count; /* # connections handled */};
你可能会问,主线程是循环在等待每个子线程完成初始化,如果进入第二个循环,等待第二个子线程完成初始化,而此时第二个子线程已经初始化完成了,该怎么办?
注意我们这里一上来是加锁的,只要取得了这把锁,同时发现event_loop_thread的eventLoop对象已经变成非NULL值,可以肯定第二个线程已经初始化,就直接释放锁往下执行了。
你可能还会问,在执行pthread_cond_wait的时候,需要持有那把锁么?这里,父线程在调用pthread_cond_wait函数之后,会立即进入睡眠,并释放持有的那把互斥锁。而当父线程再从pthread_cond_wait返回时(这是子线程通过pthread_cond_signal通知达成的),该线程再次持有那把锁。
增加已连接套接字事件到sub-reactor线程中
前面提到,主线程是一个main reactor线程,这个线程负责检测监听套接字上的事件,当有事件发生时,也就是一个连接已完成建立,如果我们有多个sub-reactor子线程,我们期望的结果是,把这个已连接套接字相关的I/O事件交给sub-reactor子线程负责检测。这样的好处是,main reactor只负责连接套接字的建立,可以一直维持在一个非常高的处理效率,在多核的情况下,多个sub-reactor可以很好地利用上多核处理的优势。
不过,这里有一个令人苦恼的问题。
我们知道,sub-reactor线程是一个无限循环的event loop执行体,在没有已注册事件发生的情况下,这个线程阻塞在event_dispatcher的dispatch上。你可以简单地认为阻塞在poll调用或者epoll_wait上,这种情况下,主线程如何能把已连接套接字交给sub-reactor子线程呢?
当然有办法。
如果我们能让sub-reactor线程从event_dispatcher的dispatch上返回,再让sub-reactor线程返回之后能够把新的已连接套接字事件注册上,这件事情就算完成了。
那如何让sub-reactor线程从event_dispatcher的dispatch上返回呢?答案是构建一个类似管道一样的描述字,让event_dispatcher注册该管道描述字,当我们想让sub-reactor线程苏醒时,往管道上发送一个字符就可以了。
在event_loop_init函数里,调用了socketpair函数创建了套接字对,这个套接字对的作用就是我刚刚说过的,往这个套接字的一端写时,另外一端就可以感知到读的事件。其实,这里也可以直接使用UNIX上的pipe管道,作用是一样的。
struct event_loop *event_loop_init() {...//add the socketfd to event 这里创建的是套接字对,目的是为了唤醒子线程eventLoop->owner_thread_id = pthread_self();if (socketpair(AF_UNIX, SOCK_STREAM, 0, eventLoop->socketPair) < 0) {LOG_ERR("socketpair set fialed");}eventLoop->is_handle_pending = 0;eventLoop->pending_head = NULL;eventLoop->pending_tail = NULL;eventLoop->thread_name = "main thread";struct channel *channel = channel_new(eventLoop->socketPair[1], EVENT_READ, handleWakeup, NULL, eventLoop);event_loop_add_channel_event(eventLoop, eventLoop->socketPair[1], channel);return eventLoop;}
要特别注意的是这句代码,这告诉event_loop的,是注册了socketPair[1]描述字上的READ事件,如果有READ事件发生,就调用handleWakeup函数来完成事件处理。
struct channel *channel = channel_new(eventLoop->socketPair[1], EVENT_READ, handleWakeup, NULL, eventLoop);
我们来看看这个handleWakeup函数:
事实上,这个函数就是简单的从socketPair[1]描述字上读取了一个字符而已,除此之外,它什么也没干。它的主要作用就是让子线程从dispatch的阻塞中苏醒。
int handleWakeup(void * data) {struct event_loop *eventLoop = (struct event_loop *) data;char one;ssize_t n = read(eventLoop->socketPair[1], &one, sizeof one);if (n != sizeof one) {LOG_ERR("handleWakeup failed");}yolanda_msgx("wakeup, %s", eventLoop->thread_name);}
现在,我们再回过头看看,如果有新的连接产生,主线程是怎么操作的?在handle_connection_established中,通过accept调用获取了已连接套接字,将其设置为非阻塞套接字(切记),接下来调用thread_pool_get_loop获取一个event_loop。thread_pool_get_loop的逻辑非常简单,从thread_pool线程池中按照顺序挑选出一个线程来服务。接下来是创建了tcp_connection对象。
//处理连接已建立的回调函数int handle_connection_established(void *data) {struct TCPserver *tcpServer = (struct TCPserver *) data;struct acceptor *acceptor = tcpServer->acceptor;int listenfd = acceptor->listen_fd;struct sockaddr_in client_addr;socklen_t client_len = sizeof(client_addr);//获取这个已建立的套集字,设置为非阻塞套集字int connected_fd = accept(listenfd, (struct sockaddr *) &client_addr, &client_len);make_nonblocking(connected_fd);yolanda_msgx("new connection established, socket == %d", connected_fd);//从线程池里选择一个eventloop来服务这个新的连接套接字struct event_loop *eventLoop = thread_pool_get_loop(tcpServer->threadPool);// 为这个新建立套接字创建一个tcp_connection对象,并把应用程序的callback函数设置给这个tcp_connection对象struct tcp_connection *tcpConnection = tcp_connection_new(connected_fd, eventLoop,tcpServer->connectionCompletedCallBack,tcpServer->connectionClosedCallBack,tcpServer->messageCallBack,tcpServer->writeCompletedCallBack);//callback内部使用if (tcpServer->data != NULL) {tcpConnection->data = tcpServer->data;}return 0;}
在调用tcp_connection_new创建tcp_connection对象的代码里,可以看到先是创建了一个channel对象,并注册了READ事件,之后调用event_loop_add_channel_event方法往子线程中增加channel对象。
tcp_connection_new(int connected_fd, struct event_loop *eventLoop,connection_completed_call_back connectionCompletedCallBack,connection_closed_call_back connectionClosedCallBack,message_call_back messageCallBack, write_completed_call_back writeCompletedCallBack) {...//为新的连接对象创建可读事件struct channel *channel1 = channel_new(connected_fd, EVENT_READ, handle_read, handle_write, tcpConnection);tcpConnection->channel = channel1;//完成对connectionCompleted的函数回调if (tcpConnection->connectionCompletedCallBack != NULL) {tcpConnection->connectionCompletedCallBack(tcpConnection);}//把该套集字对应的channel对象注册到event_loop事件分发器上event_loop_add_channel_event(tcpConnection->eventLoop, connected_fd, tcpConnection->channel);return tcpConnection;}
请注意,到现在为止的操作都是在主线程里执行的。下面的event_loop_do_channel_event也不例外,接下来的行为我期望你是熟悉的,那就是加解锁。
如果能够获取锁,主线程就会调用event_loop_channel_buffer_nolock往子线程的数据中增加需要处理的channel event对象。所有增加的channel对象以列表的形式维护在子线程的数据结构中。
接下来的部分是重点,如果当前增加channel event的不是当前event loop线程自己,就会调用event_loop_wakeup函数把event_loop子线程唤醒。唤醒的方法很简单,就是往刚刚的socketPair[0]上写一个字节,别忘了,event_loop已经注册了socketPair[1]的可读事件。如果当前增加channel event的是当前event loop线程自己,则直接调用event_loop_handle_pending_channel处理新增加的channel event事件列表。
int event_loop_do_channel_event(struct event_loop *eventLoop, int fd, struct channel *channel1, int type) {//get the lockpthread_mutex_lock(&eventLoop->mutex);assert(eventLoop->is_handle_pending == 0);//往该线程的channel列表里增加新的channelevent_loop_channel_buffer_nolock(eventLoop, fd, channel1, type);//release the lockpthread_mutex_unlock(&eventLoop->mutex);//如果是主线程发起操作,则调用event_loop_wakeup唤醒子线程if (!isInSameThread(eventLoop)) {event_loop_wakeup(eventLoop);} else {//如果是子线程自己,则直接可以操作event_loop_handle_pending_channel(eventLoop);}return 0;}
如果是event_loop被唤醒之后,接下来也会执行event_loop_handle_pending_channel函数。你可以看到在循环体内从dispatch退出之后,也调用了event_loop_handle_pending_channel函数。
int event_loop_run(struct event_loop *eventLoop) {assert(eventLoop != NULL);struct event_dispatcher *dispatcher = eventLoop->eventDispatcher;if (eventLoop->owner_thread_id != pthread_self()) {exit(1);}yolanda_msgx("event loop run, %s", eventLoop->thread_name);struct timeval timeval;timeval.tv_sec = 1;while (!eventLoop->quit) {//block here to wait I/O event, and get active channelsdispatcher->dispatch(eventLoop, &timeval);//这里处理pending channel,如果是子线程被唤醒,这个部分也会立即执行到event_loop_handle_pending_channel(eventLoop);}yolanda_msgx("event loop end, %s", eventLoop->thread_name);return 0;}
event_loop_handle_pending_channel函数的作用是遍历当前event loop里pending的channel event列表,将它们和event_dispatcher关联起来,从而修改感兴趣的事件集合。
这里有一个点值得注意,因为event loop线程得到活动事件之后,会回调事件处理函数,这样像onMessage等应用程序代码也会在event loop线程执行,如果这里的业务逻辑过于复杂,就会导致event_loop_handle_pending_channel执行的时间偏后,从而影响I/O的检测。所以,将I/O线程和业务逻辑线程隔离,让I/O线程只负责处理I/O交互,让业务线程处理业务,是一个比较常见的做法。
总结
在这一讲里,我们重点讲解了框架中涉及多线程的两个重要问题,第一是主线程如何等待多个子线程完成初始化,第二是如何通知处于事件分发中的子线程有新的事件加入、删除、修改。第一个问题通过使用锁和信号量加以解决;第二个问题通过使用socketpair,并将sockerpair作为channel注册到event loop中来解决。
思考题
和往常一样,给你布置两道思考题:
第一道, 你可以修改一下代码,让sub-reactor默认的线程个数为cpu*2。
第二道,当前选择线程的算法是round-robin的算法,你觉得有没有改进的空间?如果改进的话,你可能会怎么做?
欢迎在评论区写下你的思考,也欢迎把这篇文章分享给你的朋友或者同事,一起交流进步一下。