12|高性能优化:单机Java极致优化
你好,我是志东,欢迎和我一起从零打造秒杀系统。
今天这节课我们主要是聊一聊和Java相关的一些技术点的优化方向,包括Tomcat、RPC框架、JVM以及CDN等。但在开始之前呢,我们先来说个基本知识点,那就是关于程序代码的两种运行模式,即 CPU密集型与IO密集型。
CPU密集型操作,顾名思义就是需要持续依赖CPU资源来执行的操作,比如各种逻辑计算、解析、判断等等。在这种情况下,我们的优化方向是尽可能地利用多核CPU资源,并且避免让CPU做无效的切换,因为CPU已经在不停地工作了,谁来干都一样,同时切换CPU还浪费资源。所以这个时候,我们最好让任务线程数和CPU核数保持一致,从而最大限度地利用CPU资源。
和CPU密集型操作相对的,就是IO密集型操作了,比如磁盘IO或者网络IO,这个过程操作系统会挂起任务线程,让出CPU资源。此时如果任务线程较少,同时IO时间相对较长,那可能会出现所有线程都被挂起,然后CPU资源都在闲着的情况,所以此时我们需要适当地增加任务线程数量,来提高吞吐量,同时将CPU资源利用起来。
那为什么要说这个呢?因为这是做程序优化的基本原则。通过前面课程的学习,我们知道,秒杀系统里有提供两种类型的服务,一个是Web服务,一个是RPC服务,前者一般提供HTTP接口,后者提供RPC接口。当然这两种服务我们一般都是通过Tomcat来启动发布,但它们两者之间还是有些不同的。Web服务接受和处理请求走的是Tomcat那套线程模型,而RPC服务则是根据选择的RPC框架的不同而有所变化,所以这节课我们首先来了解一下Tomcat相关的知识。
Tomcat
根据我们以往“知己知彼”的学习方式,先看下 Tomcat在NIO线程模型下是怎么工作的,简图如下所示:
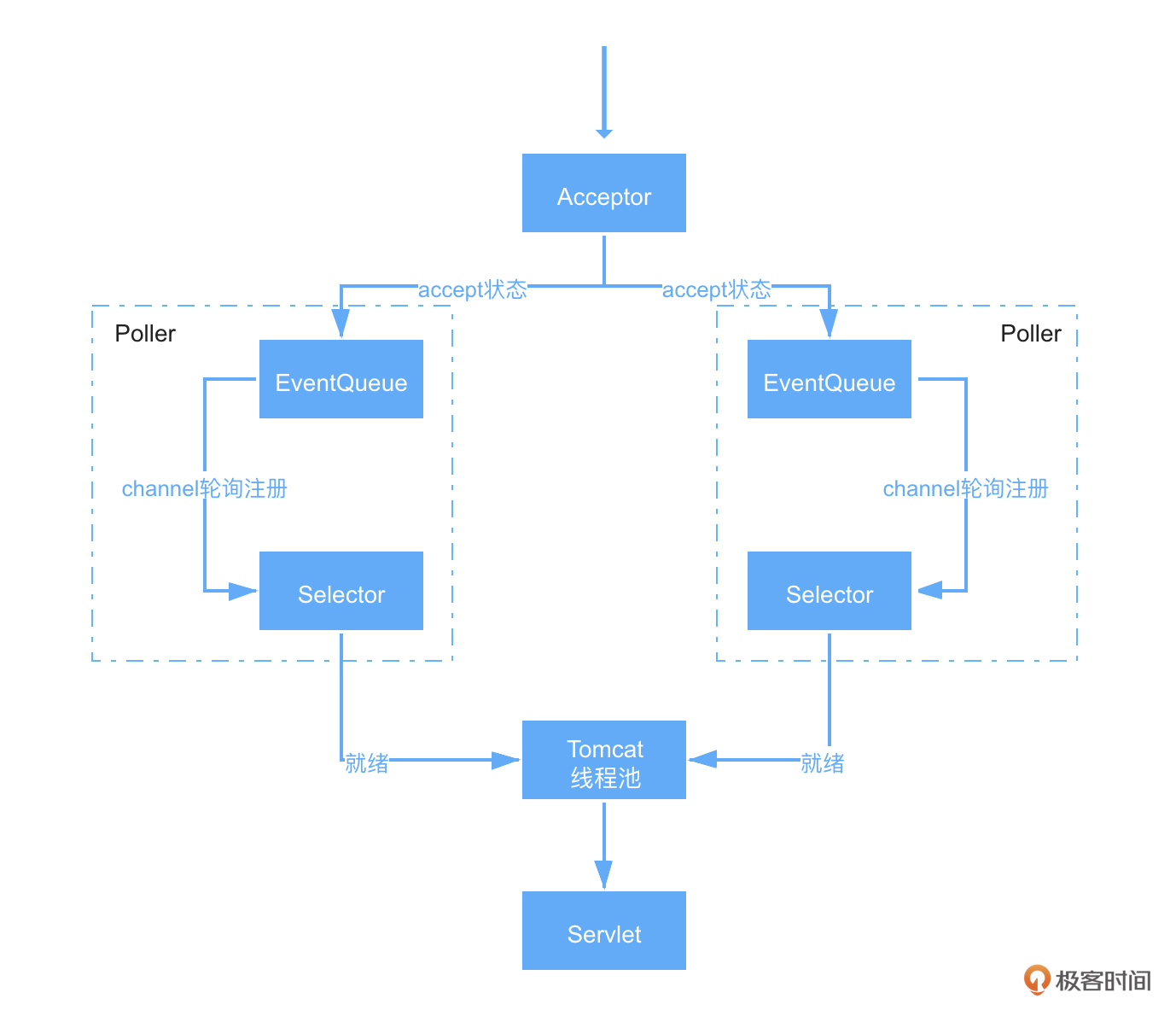
简单来说就是:
- Tomcat启动时,会创建一个Server端的Socket,来监控我们配置的端口号;
- 之后使用一个Acceptor来接受请求,然后将请求放到一个Poller下的事件队列中;
- Poller会轮询取出事件队列中的Channel,并将其注册到自身下的Selector;
- 而Selector也会不停轮询检查就绪的Channel,然后将其交给Tomcat线程池;
- Tomcat线程池会拿出一个线程来进行处理,包括解析请求头、请求体等,并将其封装进HttpServletRequest;
- 最后执行自定义的Servlet业务逻辑,执行完毕将响应结果返回。
所以从上图可以看出,所谓的非阻塞,其实就是相对以前的BIO,Tomcat不再是用一个线程将一个请求从头处理到尾,而是分阶段来执行了。好处显然易见,那就是提高了系统吞吐量。
在了解了Tomcat基本原理之后,我们再回过头来看下有什么地方是我们可以入手优化的。先看下Tomcat给我们开放了哪些可配置项:
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" />
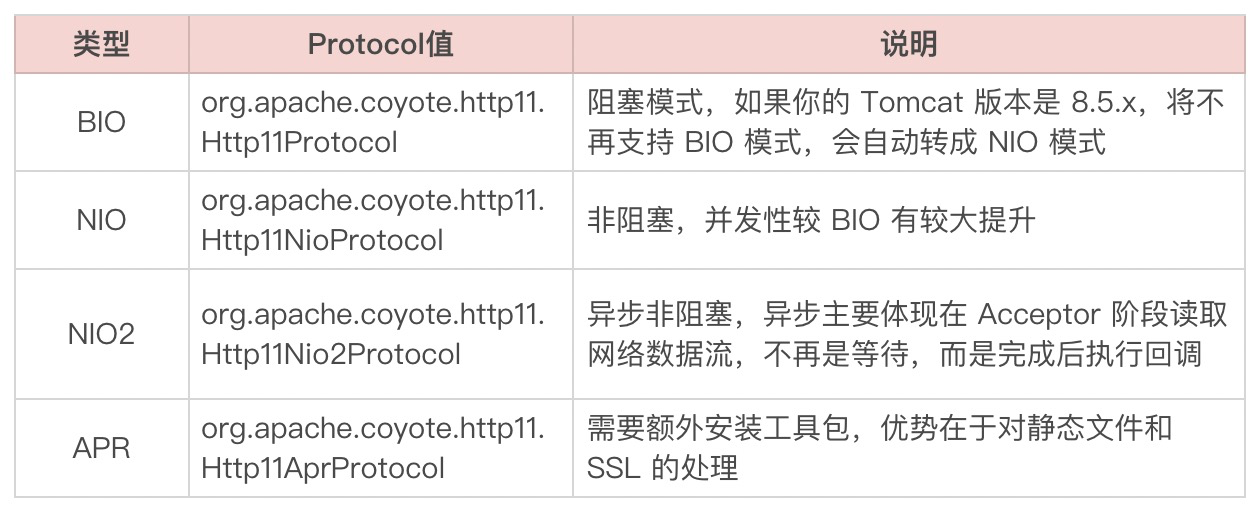
上面是Tomcat的Connector默认配置,首先是端口号,其次是protocol,也就是上面说到的线程模型。Tomcat 8之后默认使用的都是NIO模式,这个也可以通过我们服务的启动来查看:

如上图所示,就代表分别使用的是NIO模式和NIO2(AIO)模式,当然还可以选择BIO模式以及APR模式。具体对比可参考下表:
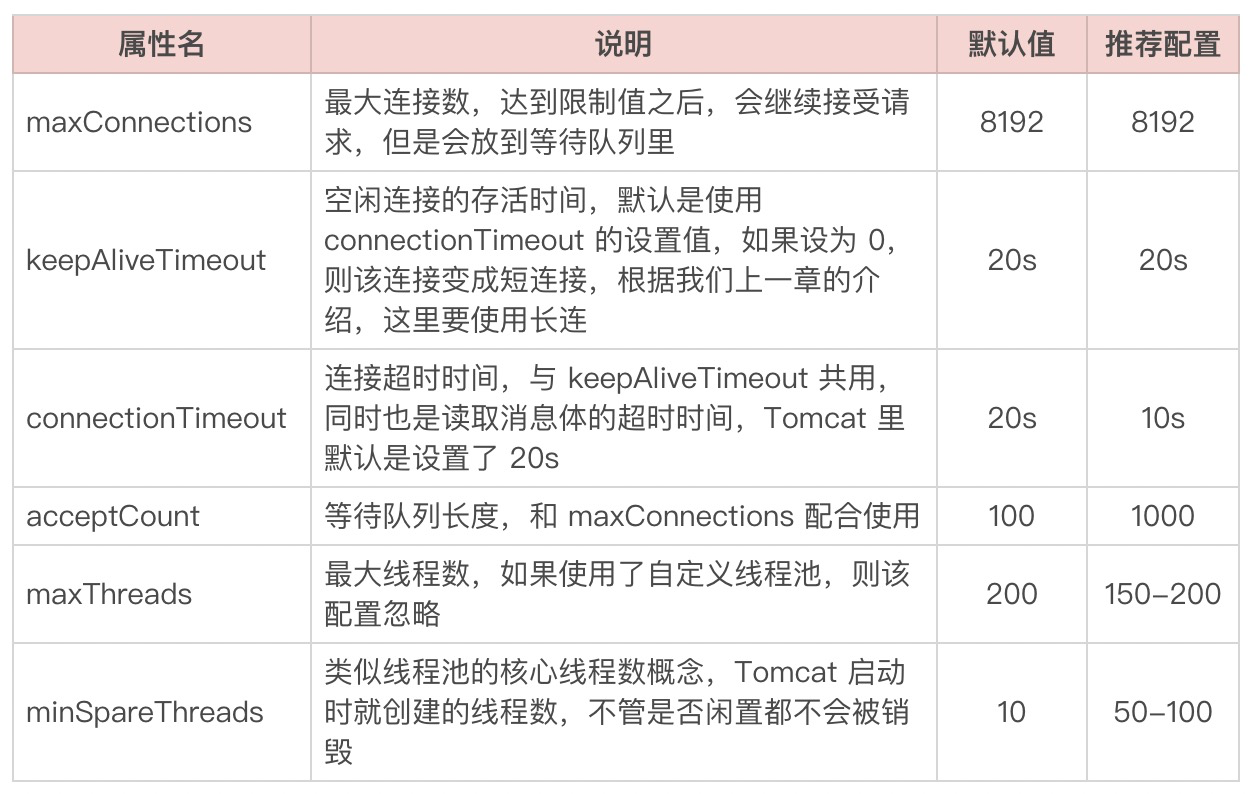
那说完线程模型的选择,从上图中我们可以看到有个Tomcat线程池的概念,它是通过哪些配置来控制的呢?这里我们只摘几个重要的配置说一下,详细信息如下表所示:
说完了Tomcat的配置,这里再简单说说 Servlet 的部分知识。我们都知道Servlet从3.0开始加入了异步,从3.1开始又新增了对IO非阻塞的支持,那么这个和Tomcat线程模型中提到的异步非阻塞是一个概念吗?这里我们就来捋一捋。
首先从上面的Tomcat线程模型图中,我们可以清晰地看到,NIO或AIO的概念是针对请求的接收来说,而Servlet的异步非阻塞主要是针对请求的处理,已经是到了Tomcat线程池那里了。
我们先来看下Servlet3.0前后的变化对比,如下图所示:
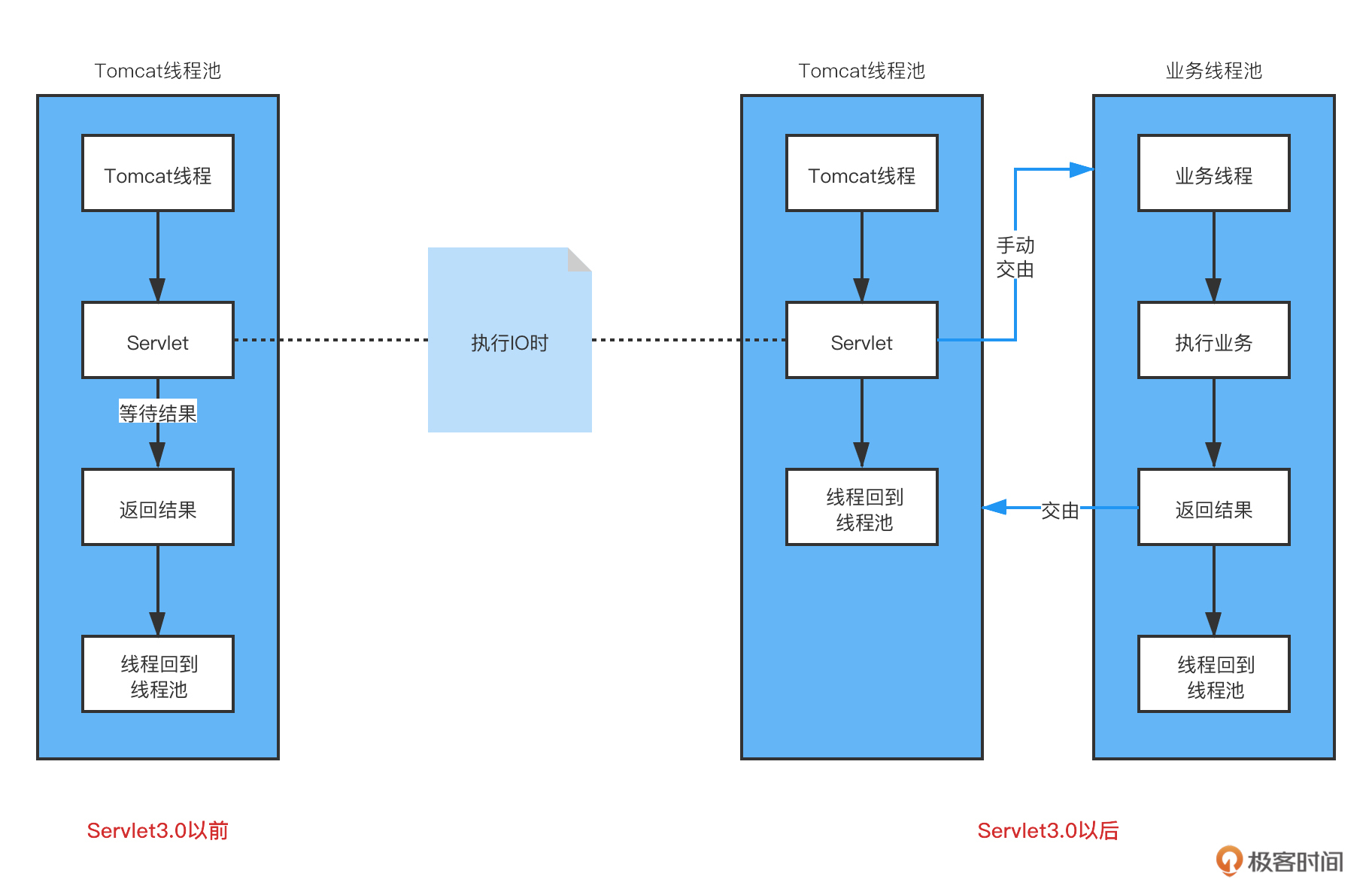
概述一下就是,Servlet3.0之前,Tomcat线程在执行自定义Servlet时,如果过程中发生了IO,那么Tomcat线程只能在那等着结果,这时线程是被挂起的,如果被挂起的多了,自然会影响对其他请求的处理。
所以在Servlet3.0之后,支持在这种情况下将这种等待的任务交给一个自定义的业务线程池去做,这样Tomcat线程可以很快地回到线程池,处理其他请求。而业务线程在执行完业务逻辑以后,通过调用指定的方法,告诉Tomcat线程池接下来可以将业务线程执行的结果返回给调用方,这样就实现了同步转异步的效果。
这样做的好处,可能对提高系统的吞吐量有一定帮助,但从JVM层面来说,并没有减少工作量。业务线程在执行任务遇到IO时,依然会阻塞,现在只是由业务线程池代替了Tomcat线程池做了最耗时的那部分工作,这样也许可以将原来的200个Tomcat线程,拆分成20个Tomcat线程、180个业务线程来配合工作。这里原生Servlet以及SpringMVC对异步功能支持的测试代码,你可以看GitHub代码库中的AsyncServlet类和TestAsyncController类,相信你一看就明白了。
接着我们再聊一下Servlet3.1的非阻塞,这块简单来说,就是针对请求消息体的读取,这是个IO过程,以前是阻塞式读取,现在支持非阻塞读取了。实现的大致原理就是在读取数据时,新增一个监听事件,在读取完成后由Tomcat线程执行回调。
在了解了Tomcat线程模型之后,我们接着再说下RPC框架相关的知识。
RPC框架
虽然RPC服务处理请求的过程,会依据选用的RPC框架而有所不同,但绝大部分RPC框架底层使用的都是Netty,而Netty则是基于NIO开发的一种网络通信框架,支持多种通信协议,其服务端线程模型简略图如下所示:
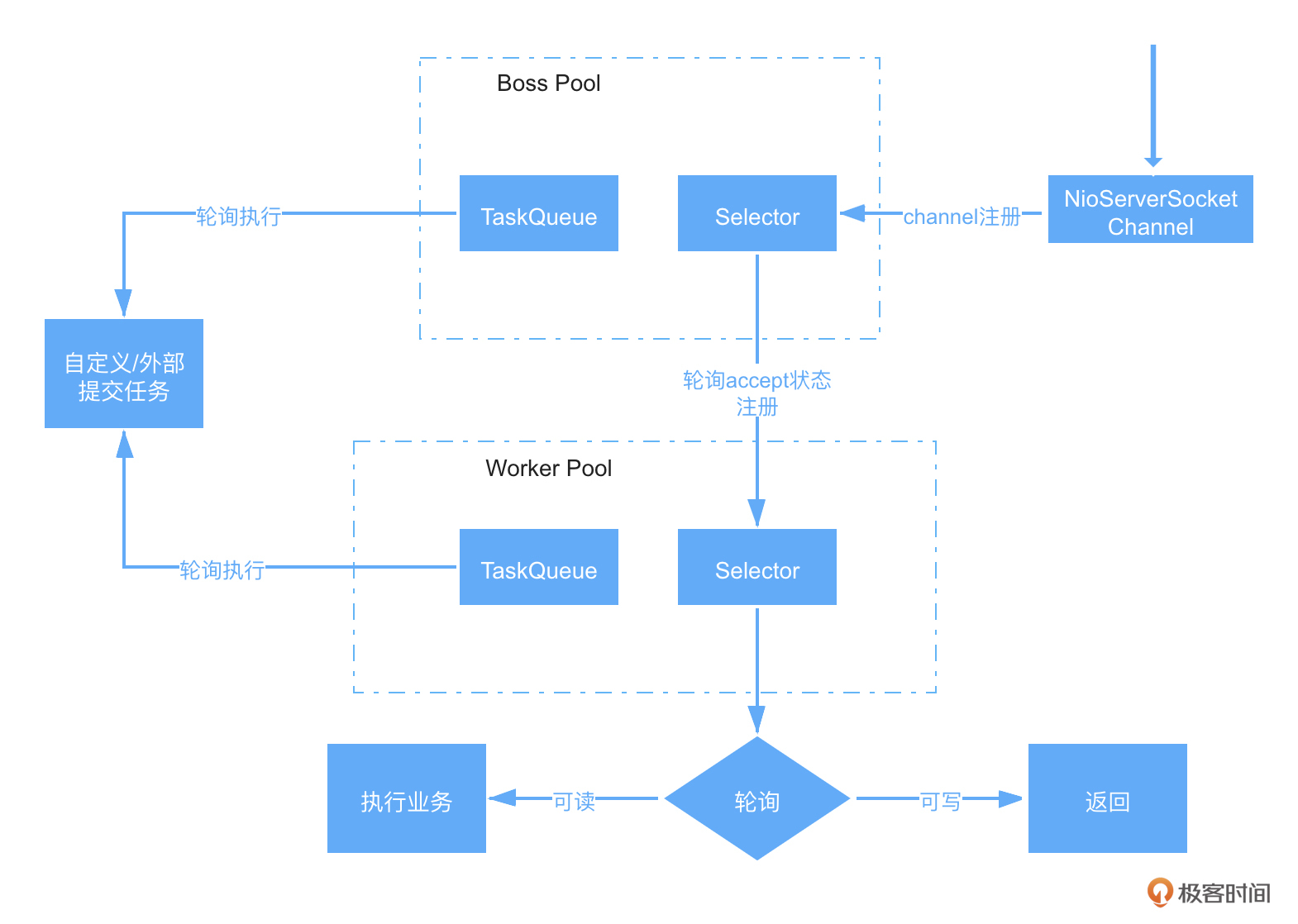
简单描述就是:
- 在服务启动时,会创建一个Server端Socket,监控我们配置的端口号;
- 然后将NioServerSocketChannel注册到Boss Pool中的一个Selector上;
- 再之后对Selector做轮询,将就绪状态的连接封装成NioSocketChannel并注册到Worker Pool下的一个Selector上;
- 而Worker Pool下的Selector也是同样轮询,找出可读和可写状态的分别执行不同操作。
- 同时两个Pool中都有任务队列,是不同场景下用户自定义或外部通过特定方式提交过去的任务,都会被依次执行。
所以当我们的应用只提供RPC服务时,我们可以将Tomcat的核心线程池配置,也就是minSpareThreads配置成1,因为用不到。而我们主要需要调整的是RPC框架的相关配置,以Dubbo为例,我们看下 <dubbo:protocol> 的主要配置项:
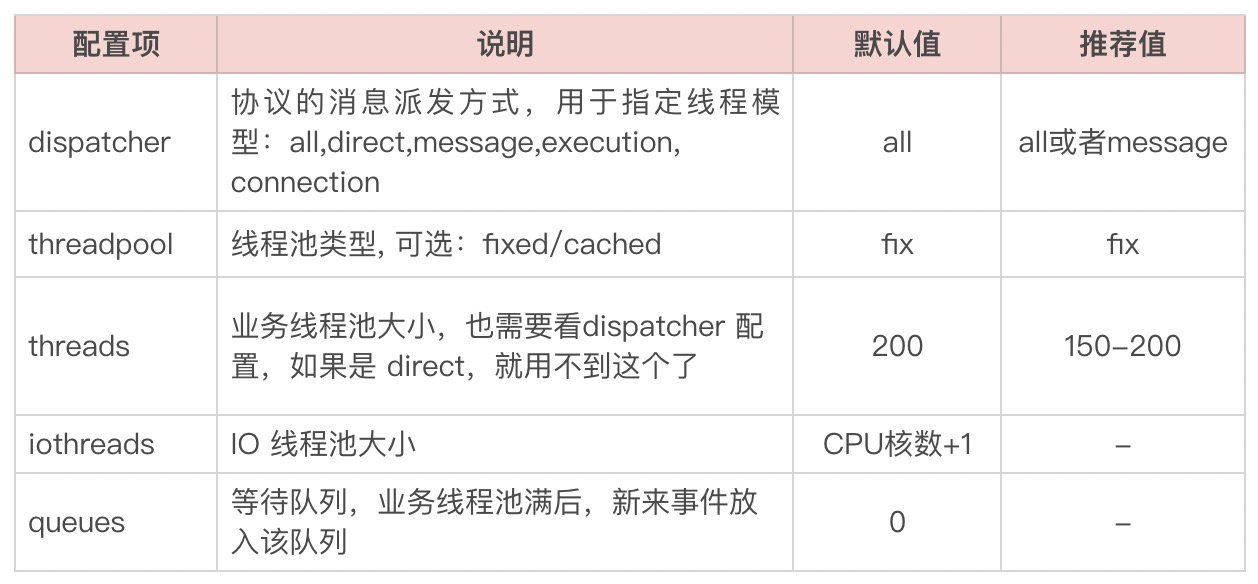
在Netty中,虽然只有一个Worker Pool,但会做两种类型的事情,一个是做IO处理,包括请求消息的读写,另一个是做业务逻辑处理。
而Dubbo将其分成了两个线程池,也就是上面表格中的两个线程池配置。这两个线程池做的事情,会根据Dispatcher的配置而有所不同。Netty是以事件驱动的形式来工作的,像请求、响应、连接、断开、异常等操作都是事件;而Dubbo中的Dispatcher就是将不同的事件类型分给不同的线程池来处理,如果你感兴趣的话可以去看下Dubbo中WrappedChannelHandler类的5个实现类,分别对应Dispatcher的5个选项。
最后一个配置项Queues,这个默认值是0,也就是不接受等待,如果没有空闲线程处理任务,将会直接返回。这个得和客户端配置配合使用,如果这里配置了0,那客户端最好配置重试。
讲完了两种服务的底层线程模型之后,我们再来介绍一下静态资源相关的优化。
静态资源
我们知道在秒杀系统中,客户端与服务端既有动态数据交互,也有静态数据交互,而我们做系统优化有个基本的原则,即前后端交互越少,数据越小,链路越短,数据离用户越近,响应就越快。
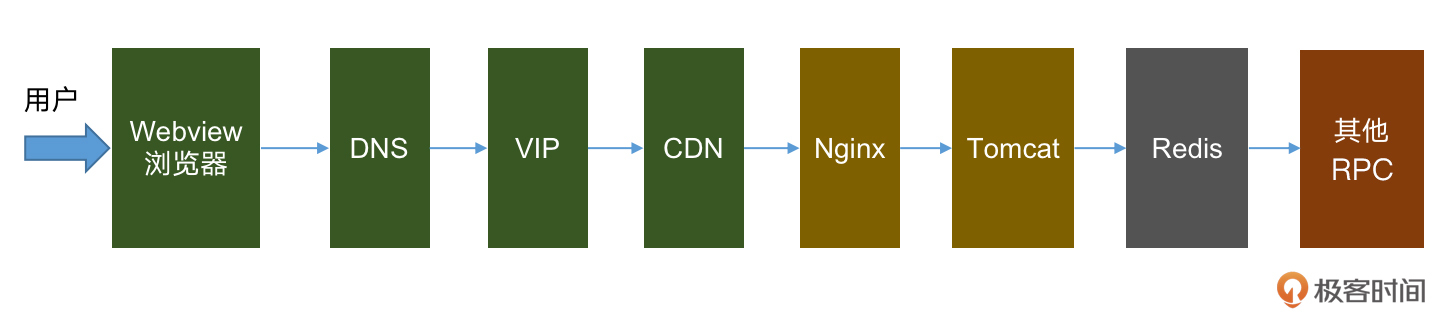
基于这个原则,针对以上的静态数据,我们就可以把静态文件CDN化,资源前移到全国各地的CDN节点上,用户秒杀的时候就近进行下载,就不需要都挤到中心的Tomcat服务器上了。
静态资源前移,大家平常也会做,感受比较深的是不是就是客户端的页面加载更快了,但除了性能的提升外,其实它对系统稳定也至关重要。
试想一下,当几百万人同时来拉取这些较大的资源文件时,对中心的Tomcat服务器以及公司的网络带宽都是巨大的压力。京东当初在进行口罩抢购的时候,这些静态资源就差点把公司的出口带宽打满,影响交易大盘,后来紧急扩容才避免了危机。
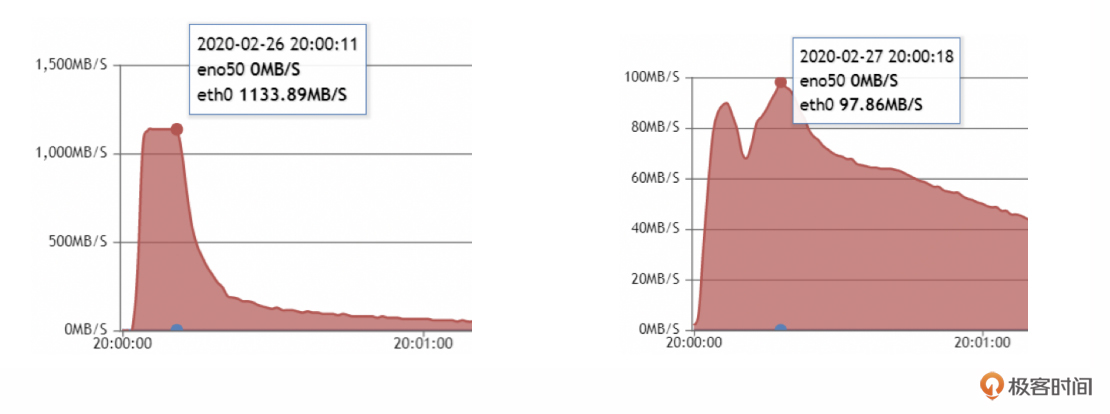
另外,这些静态资源对Tomcat所在物理机的网卡挑战也很大,京东在资源CDN化前,物理机的万兆网卡曾被打满,后来经过优化之后,网卡的流量只有原来的10%了。
在最后,我们再说下Java运行的基础环境,JVM相关的知识以及优化。
JVM
这里如果你对一些基本概念,比如JVM内存结构、GC原理、垃圾收集器类型等还不了解,那建议你先了解一下,会有事半功倍的效果。这块的内容比较多,又比较重要,但我们没办法一一展开,只说最核心的优化点。
先看个JVM内存模型以及常用配置,如下图所示:
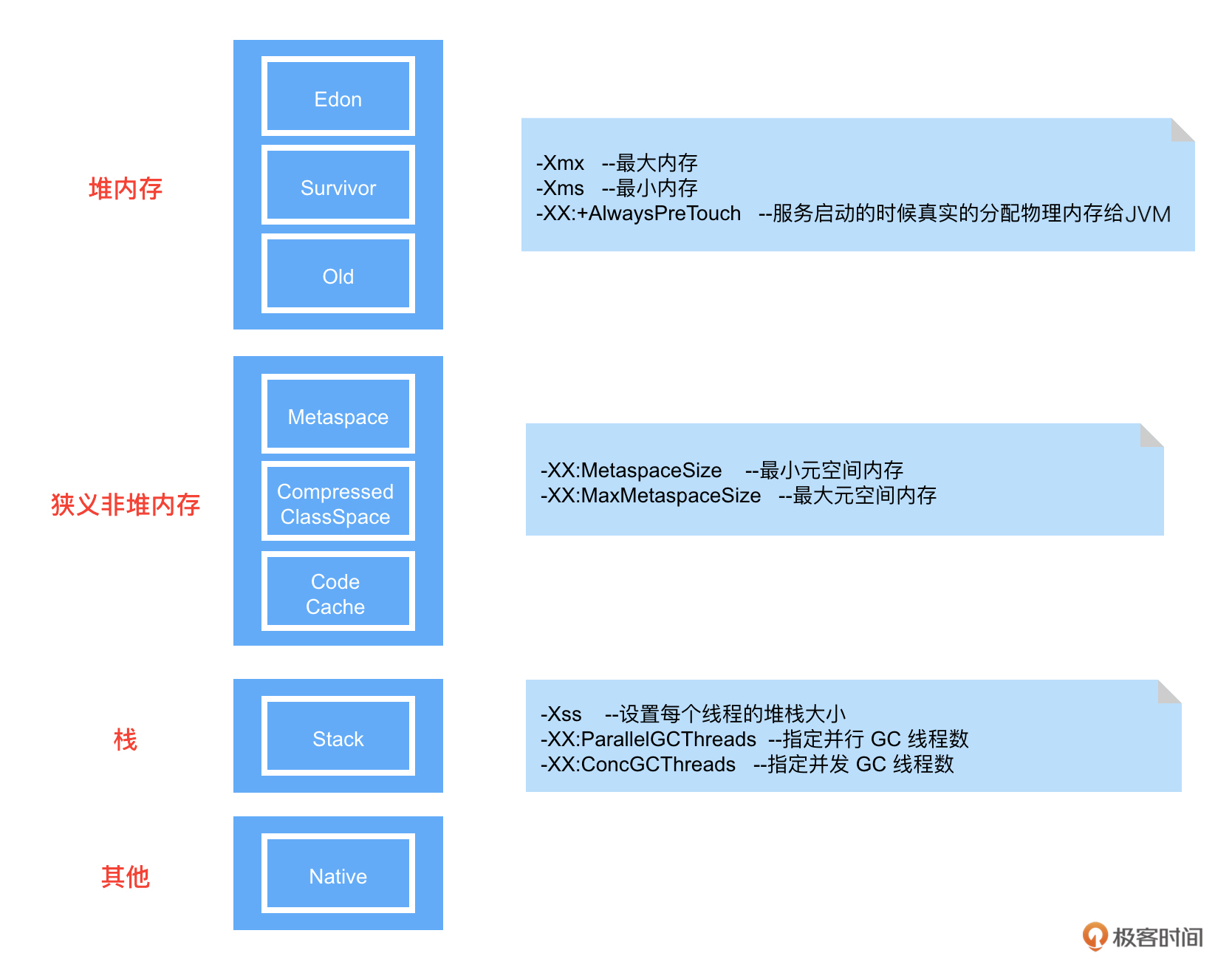
其实针对JVM的优化,我们最关心的无非就两个问题,一个是垃圾回收器怎么选择,另一个就是对选择的垃圾回收器如何做优化。这里我们分别讲一下。
对于垃圾回收器的选择,是需要分业务场景的。如果我们提供的服务对响应时间敏感,并且堆内存能够给到8G以上的,那建议选择G1;堆内存较小或JDK版本较低的,可以选择CMS。相反如果对响应时间不敏感,追求一定的吞吐量的,则建议选择ParallelGC,同时这也是JDK8的默认垃圾回收器。
选择完垃圾回收器之后,接下来就针对不同的垃圾回收器,分别做不同的参数优化。
首先是ParallelGC,其主要配置参数如下:
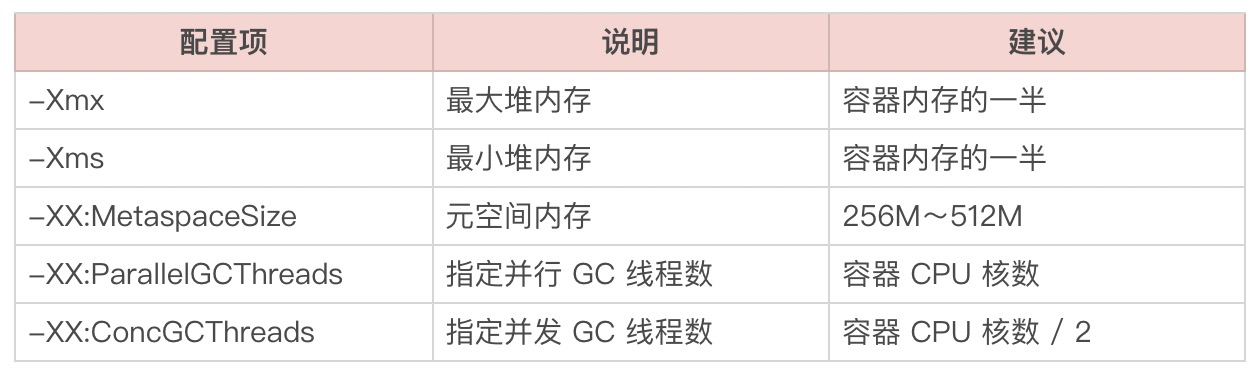
然后是CMS,在ParallelGC配置参数的基础上增加以下配置:
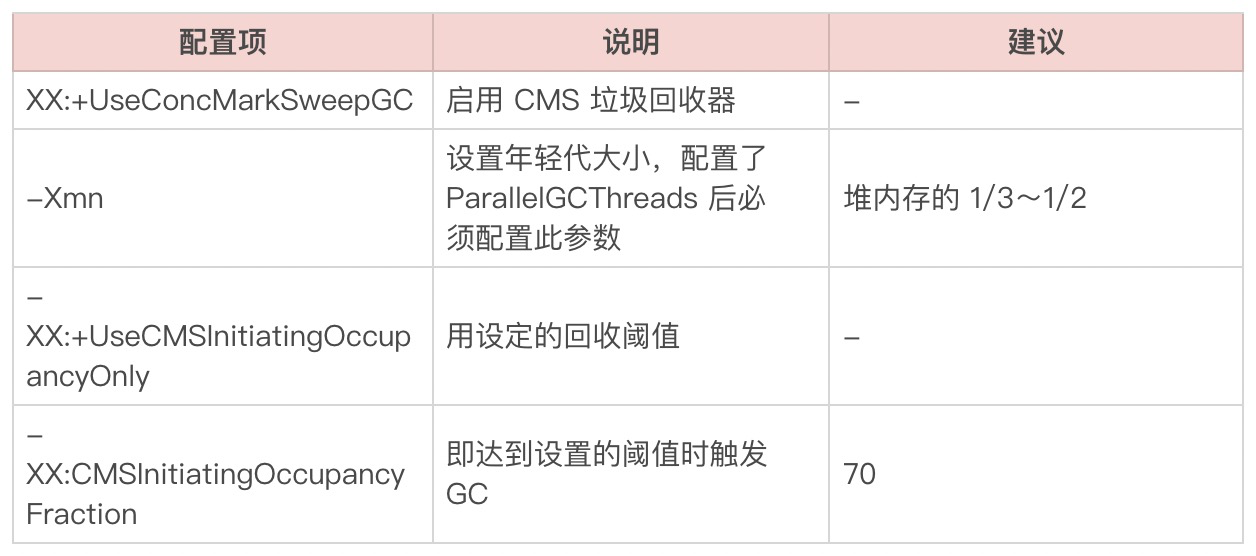
再说下G1的优化配置(在使用了G1的情况下,就不要设置 -Xmn 和 XX:NewRatio了),同样是在ParallelGC配置参数的基础上增加以下配置:

因为我们秒杀的业务场景更适合选择G1来做垃圾回收器,那这里也给一个在8核16G容器下的JVM配置,具体如下:
-Xms8192m -Xmx8192m -XX:MaxMetaspaceSize=512m -XX:+UseG1GC -XX:ParallelGCThreads=8 -XX:ConcGCThreads=4 -XX:G1HeapRegionSize=8m
总结
今天主要围绕着Java,对与其息息相关的Tomcat、JVM、RPC框架以及静态资源的优化,做了分析和讲解。
对于Tomcat的优化,在秒杀的特定业务场景下针对线程模型的选择,从理论和实际压测上看,NIO2比NIO是有吐吞量的提升,但不是很大,如果为了省事,选择默认的NIO即可。而APR的话,因为我们静态资源都上到CDN了,并且Web服务并不直接对外(请求由Nginx转发过来),也不要求是HTTPS方式,所以这里也不考虑了,和线程池相关的配置,最好按照这节课中的建议做适当的调整。
同时我们也提到了Servlet在3.0和3.1版本提供的异步非阻塞功能,由于秒杀的接口入参不涉及文件之类的较大消息体,所以IO非阻塞可以不用。而异步功能这块,其实可以有更好的选择,那就是Vertx技术,这也是我们在下节课中,将会单独介绍的一种异步化编程思想技术。
而对于RPC框架,我们主要介绍了基于NIO开发的一种网络通信框架Netty,了解了Netty主要使用两个池子,即使用Boss Pool和Worker Pool来实现Reactor模式。同时选择了一个具体的RPC框架Dubbo,来做了详细的配置优化讲解。
在聊完了两种服务的底层线程模型与优化后,我们介绍了静态资源的优化方案,即将静态资源上到CDN,以减轻对秒杀域名流量的压力,同时可以依靠CDN的全国部署,快速加载到对应的静态资源。
另外,我们还提到了Java运行的环境JVM,包括垃圾回收器的选择与优化,即如果我们提供的服务对响应时间敏感,并且堆内存能够给到8G以上的,那就选择G1;而堆内存较小或JDK版本较低的,可以选择CMS。相反如果对响应时间不敏感,追求一定的吞吐量的,则建议选择ParallelGC。同时针对不同的垃圾回收器,也给出了对应的优化配置。
当然以上所有的优化建议,在调整后都需要做实际业务场景下的压测,毕竟实践才是检测真理的唯一标准!
思考题
这节课我们介绍了通过Tomcat发布的Web服务和RPC服务,两者走的底层线程模型是不同的,如果我们的服务既提供HTTP接口,也提供RPC接口,我们该通过何种方式才能将二者的相互影响降至最低呢?
期待你的思考,也欢迎在留言区中分享讨论。我们下节课再见!