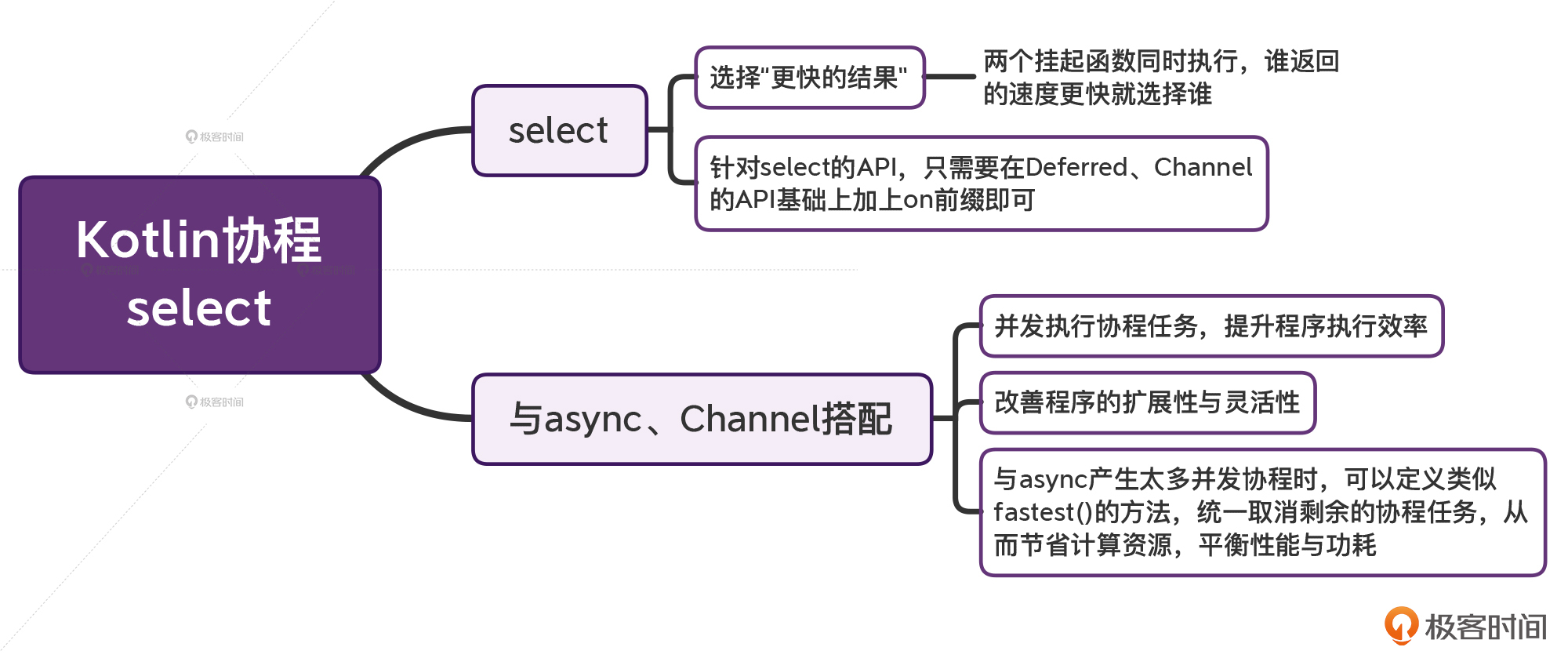
21 | select:到底是在选择什么?
你好,我是朱涛。今天我们来学习Kotlin协程的select。
select,在目前的Kotlin 1.6当中,仍然是一个实验性的特性(Experimental)。但是,考虑到select具有较强的实用性,我决定还是来给你介绍一下它。
select可以说是软件架构当中非常重要的一个组件,在很多业务场景下,select与Deferred、Channel结合以后,在大大提升程序的响应速度的同时,还可以提高程序的灵活性、扩展性。
今天这节课,我会从select的使用角度着手,带你理解select的核心使用场景,之后也会通过源码帮你进一步分析select API的底层规律。学完这节课以后,你完全可以将select应用到自己的工作当中去。
好,接下来,我们就一起来学习select吧!
select就是选择“更快的结果”
由于select的工作机制比较抽象,我们先来假设一个场景,看看select适用于什么样的场景。
客户端,想要查询一个商品的详情。目前有两个服务:缓存服务,速度快但信息可能是旧的;网络服务,速度慢但信息一定是最新的。
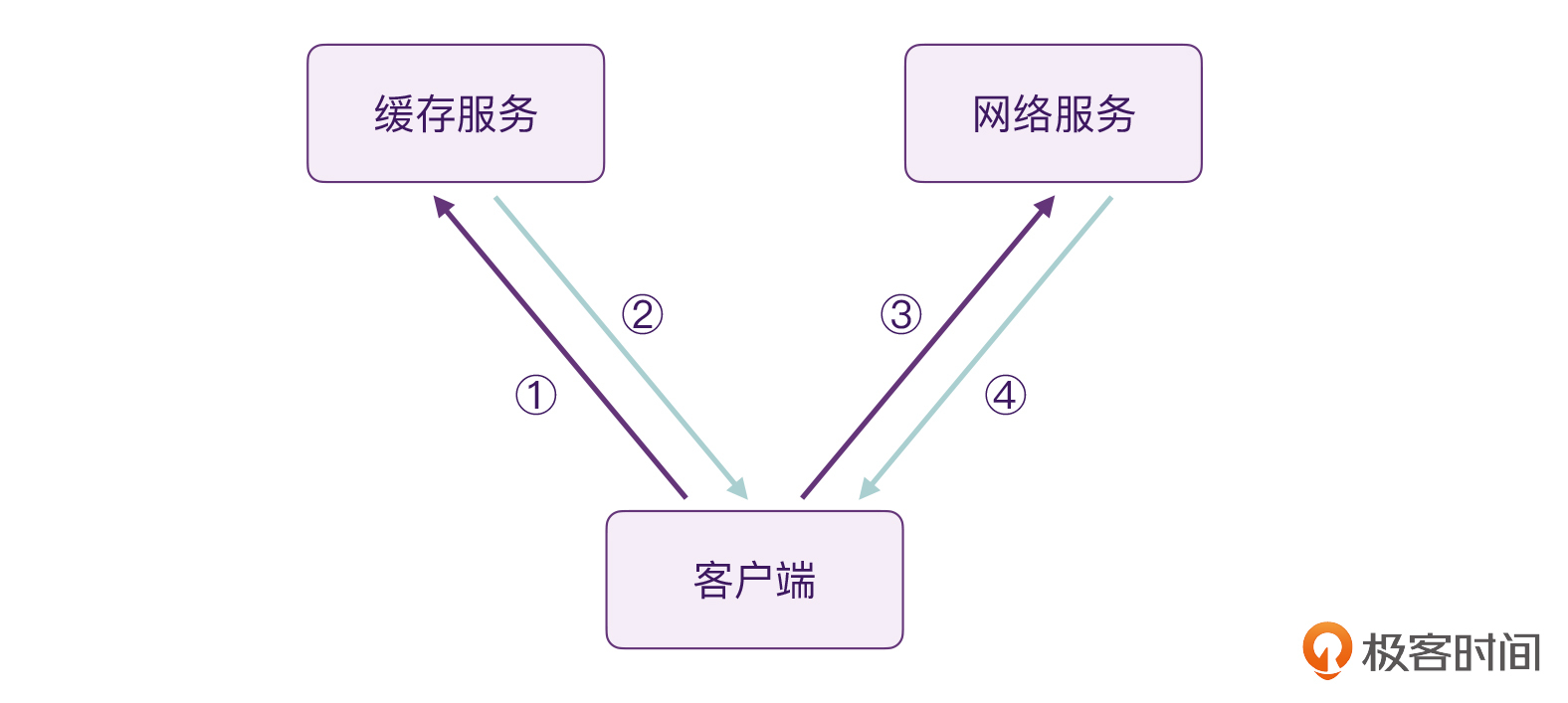
对于这个场景,如果让我们来实现其中的逻辑的话,我们非常轻松地就能实现类似这样的代码逻辑:
// 代码段1fun main() = runBlocking {suspend fun getCacheInfo(productId: String): Product? {delay(100L)return Product(productId, 9.9)}suspend fun getNetworkInfo(productId: String): Product? {delay(200L)return Product(productId, 9.8)}fun updateUI(product: Product) {println("${product.productId}==${product.price}")}val startTime = System.currentTimeMillis()val productId = "xxxId"// 查询缓存val cacheInfo = getCacheInfo(productId)if (cacheInfo != null) {updateUI(cacheInfo)println("Time cost: ${System.currentTimeMillis() - startTime}")}// 查询网络val latestInfo = getNetworkInfo(productId)if (latestInfo != null) {updateUI(latestInfo)println("Time cost: ${System.currentTimeMillis() - startTime}")}}data class Product(val productId: String,val price: Double)/*输出结果xxxId==9.9Time cost: 112xxxId==9.8Time cost: 314*/
考虑到缓存服务速度更快,我们自然而然会这么写,先去查询缓存服务,如果查询到了信息,我们就会去更新UI界面。之后去查询网络服务,拿到最新的信息之后,我们再来更新UI界面。也就是这样:
- 第一步:查询缓存信息;
- 第二步:缓存服务返回信息,更新UI;
- 第三步:查询网络服务;
- 第四步:网络服务返回信息,更新UI。
这种做法的好处在于,用户可以第一时间看到商品的信息,虽然它暂时会展示旧的信息,但由于我们同时查询了网络服务,旧缓存信息也马上会被替代成新的信息。这样的做法,可以最大程度保证用户体验。
不过,以上整个流程都是建立在“缓存服务一定更快”的前提下的,万一我们的缓存服务出了问题,它的速度变慢了,甚至是超时、无响应呢?
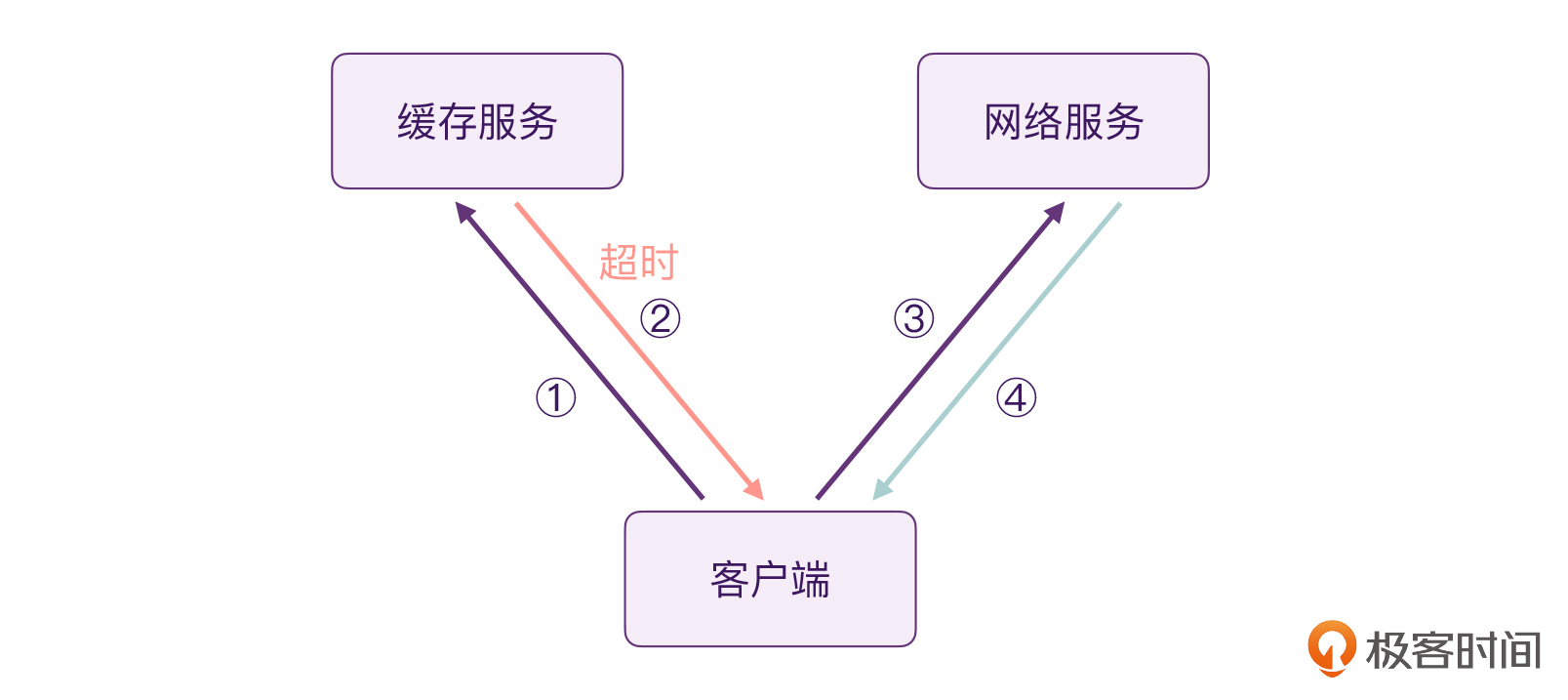
这时候,如果你回过头来分析代码段1的话,你就会发现:程序执行流程会卡在第二步,迟迟无法进行第三步。具体来说,是因为getCacheInfo()它是一个挂起函数,只有这个程序执行成功以后,才可以继续执行后面的任务。你也可以把getCacheInfo()当中的delay时间修改成2000毫秒,去验证一下。
/*执行结果:xxxId==9.9Time cost: 2013xxxId==9.8Time cost: 2214*/
那么,面对这样的场景,我们其实需要一个可以灵活选择的语法:“两个挂起函数同时执行,谁返回的速度更快,我们就选择谁”。这其实就是select的典型使用场景。
select和async
上面的这个场景,我们可以用async搭配select来使用。async可以实现并发,select则可以选择最快的结果。
让我们来看看,代码具体该怎么写。
// 代码段2fun main() = runBlocking {val startTime = System.currentTimeMillis()val productId = "xxxId"// 1,注意这里// ↓val product = select<Product?> {// 2,注意这里async { getCacheInfo(productId) }.onAwait { // 3,注意这里it}// 4,注意这里async { getNetworkInfo(productId) }.onAwait { // 5,注意这里it}}if (product != null) {updateUI(product)println("Time cost: ${System.currentTimeMillis() - startTime}")}}/*输出结果xxxId==9.9Time cost: 127*/
从上面的执行结果,我们可以看到,由于缓存的服务更快,所以,select确实帮我们选择了更快的那个结果。代码中一共有四个注释,我们一起来看看:
- 注释1,我们使用select这个高阶函数包裹了两次查询的服务,同时传入了泛型参数Product,代表我们要选择的数据类型是Product。
- 注释2,4中,我们使用了async包裹了getCacheInfo()、getNetworkInfo()这两个挂起函数,这是为了让这两个查询实现并发执行。
- 注释3,5中,我们使用onAwait{} 将执行结果传给了select{},而select才能进一步将数据返回给product局部变量。注意了,这里我们用的onAwait{},而不是await()。
现在,假设,我们的缓存服务出现了问题,需要2000毫秒才能返回:
// 代码段3suspend fun getCacheInfo(productId: String): Product? {// 注意这里delay(2000L)return Product(productId, 9.9)}/*输出结果xxxId==9.8Time cost: 226*/
这时候,通过执行结果,我们可以发现,我们的select可以在缓存服务出现问题的时候,灵活选择网络服务的结果。从而避免用户等待太长的时间,得到糟糕的体验。
不过,你也许发现了,“代码段1”和“代码段2”其实并不是完全等价的。因为在代码段2当中,用户大概率是会展示旧的缓存信息。但实际场景下,我们是需要进一步更新最新信息的。
其实,在代码段2的基础上,我们也可以轻松实现,只是说,这里我们需要为Product这个数据类增加一个标记。
// 代码段4data class Product(val productId: String,val price: Double,// 是不是缓存信息val isCache: Boolean = false)
然后,我们还需要对代码段2的逻辑进行一些提取:
// 代码段5fun main() = runBlocking {suspend fun getCacheInfo(productId: String): Product? {delay(100L)return Product(productId, 9.9)}suspend fun getNetworkInfo(productId: String): Product? {delay(200L)return Product(productId, 9.8)}fun updateUI(product: Product) {println("${product.productId}==${product.price}")}val startTime = System.currentTimeMillis()val productId = "xxxId"// 1,缓存和网络,并发执行val cacheDeferred = async { getCacheInfo(productId) }val latestDeferred = async { getNetworkInfo(productId) }// 2,在缓存和网络中间,选择最快的结果val product = select<Product?> {cacheDeferred.onAwait {it?.copy(isCache = true)}latestDeferred.onAwait {it?.copy(isCache = false)}}// 3,更新UIif (product != null) {updateUI(product)println("Time cost: ${System.currentTimeMillis() - startTime}")}// 4,如果当前结果是缓存,那么再取最新的网络服务结果if (product != null && product.isCache) {val latest = latestDeferred.await()?: return@runBlockingupdateUI(latest)println("Time cost: ${System.currentTimeMillis() - startTime}")}}/*输出结果:xxxId==9.9Time cost: 120xxxId==9.8Time cost: 220*/
如果你对比代码段1和代码段5的执行结果,会发现代码段5的总体耗时更短。
另外在上面的代码中,还有几个注释,我们一个个看:
- 首先看注释1,我们将getCacheInfo()、getNetworkInfo()提取到了select的外部,让它们通过async并发执行。如果你还记得第16讲思考题当中的逻辑,你一定可以理解这里的async并发。(如果你忘了,可以回过头去看看。)
- 注释2,我们仍然是通过select选择最快的那个结果,接着在注释3这里我们第一时间更新UI界面。
- 注释4,我们判断当前的product是不是来自于缓存,如果是的话,我们还需要用最新的信息更新UI。
然后在这里,假设我们的缓存服务出现了问题,需要2000毫秒才能返回:
// 代码段6suspend fun getCacheInfo(productId: String): Product? {// 注意这里delay(2000L)return Product(productId, 9.9)}/*输出结果xxxId==9.8Time cost: 224*/
可以看到,代码仍然可以正常执行。其实,当前的这个例子很简单,不使用select同样也可以实现。不过,select这样的代码模式的优势在于,扩展性非常好。
下面,我们可以再来假设一下,现在我们有了多个缓存服务。
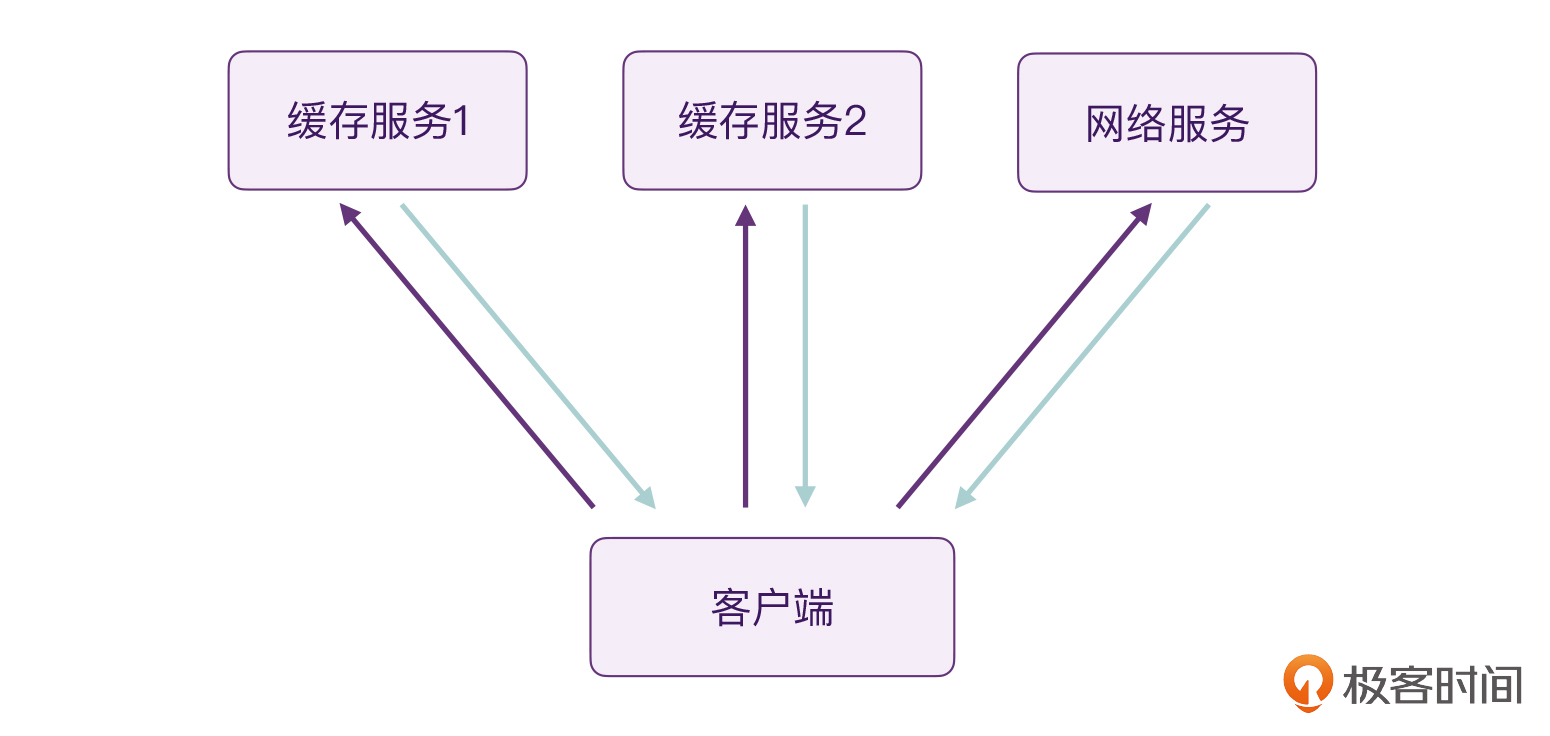
对于这个问题,我们其实只需要稍微改动一下代码段3就行了。
// 代码段7fun main() = runBlocking {val startTime = System.currentTimeMillis()val productId = "xxxId"val cacheDeferred = async { getCacheInfo(productId) }// 变化在这里val cacheDeferred2 = async { getCacheInfo2(productId) }val latestDeferred = async { getNetworkInfo(productId) }val product = select<Product?> {cacheDeferred.onAwait {it?.copy(isCache = true)}// 变化在这里cacheDeferred2.onAwait {it?.copy(isCache = true)}latestDeferred.onAwait {it?.copy(isCache = false)}}if (product != null) {updateUI(product)println("Time cost: ${System.currentTimeMillis() - startTime}")}if (product != null && product.isCache) {val latest = latestDeferred.await() ?: return@runBlockingupdateUI(latest)println("Time cost: ${System.currentTimeMillis() - startTime}")}}/*输出结果xxxId==9.9Time cost: 125xxxId==9.8Time cost: 232*/
可以看到,当增加一个缓存服务进来的时候,我们的代码只需要做很小的改动,就可以实现。
所以,总的来说,对比传统的挂起函数串行的执行流程,select这样的代码模式,不仅可以提升程序的整体响应速度,还可以大大提升程序的灵活性、扩展性。
select和Channel
在前面的课程我们提到过,在协程中返回一个内容的时候,我们可以使用挂起函数、async,但如果要返回多个结果的话,就要用Channel和Flow。
那么,这里我们来看看select和Channel的搭配使用。这里,我们有两个管道,channel1、channel2,它们里面的内容分别是1、2、3;a、b、c,我们通过select,将它们当中的数据收集出来并打印。
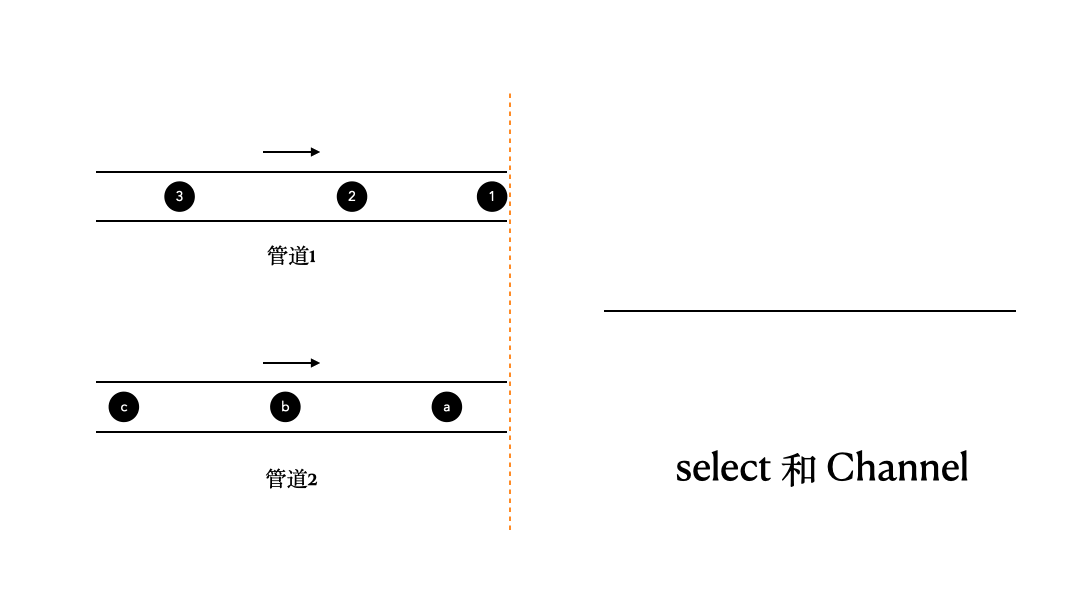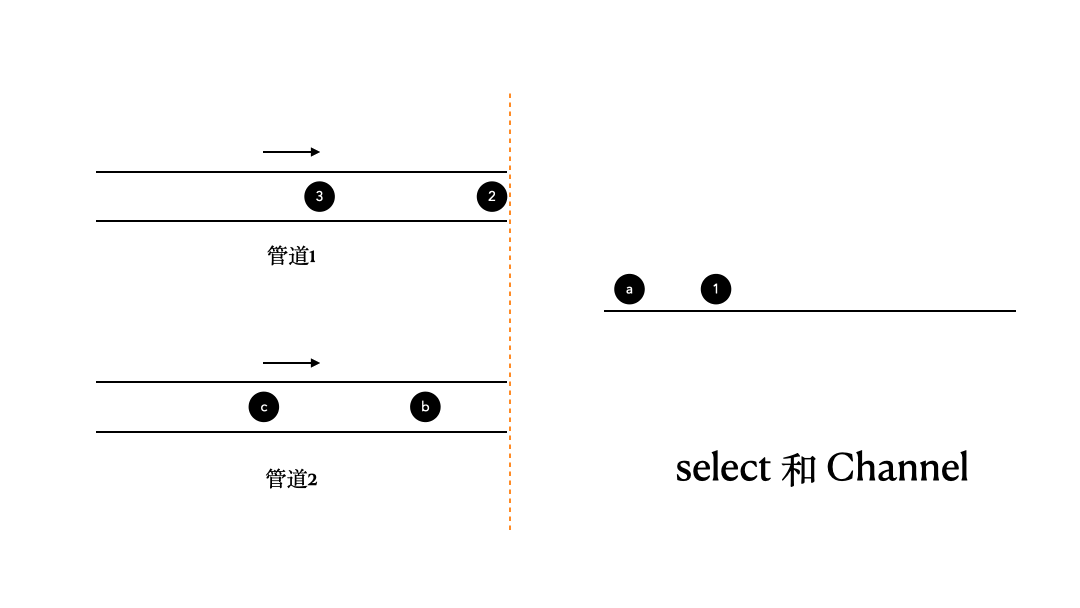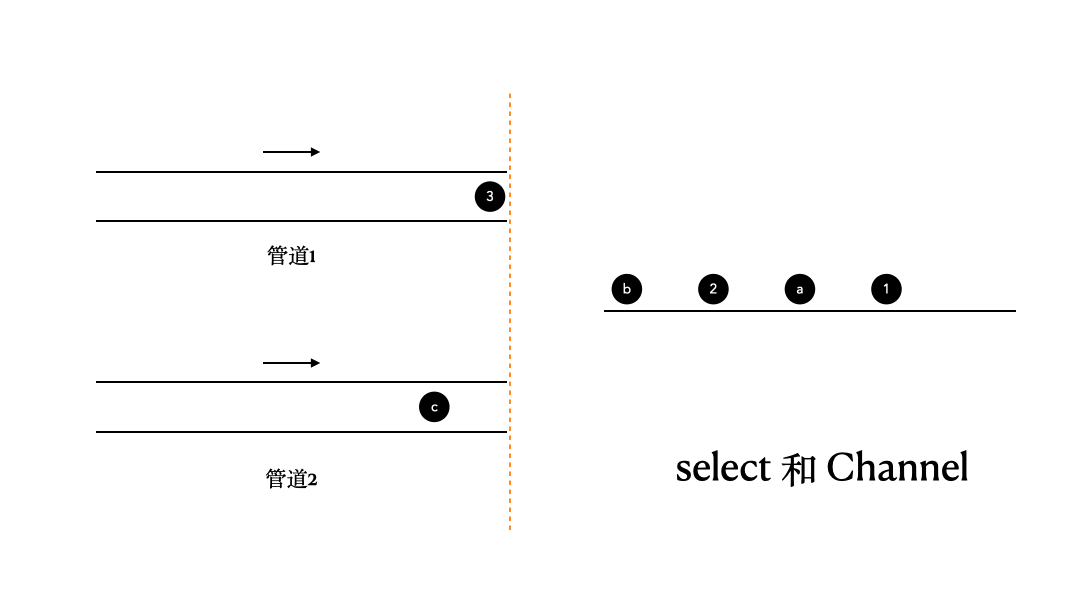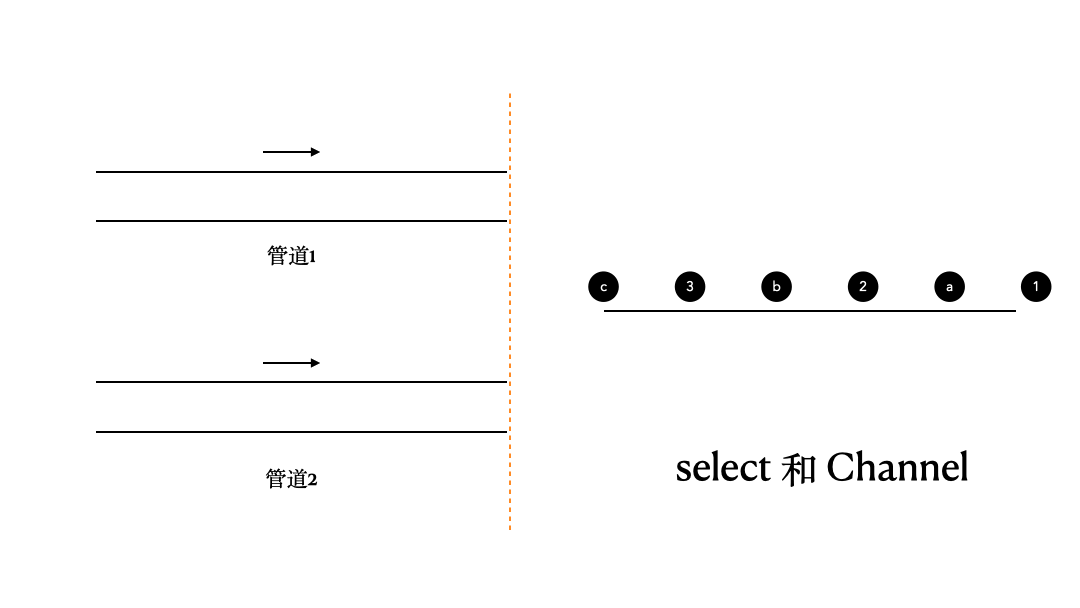
对于这个问题,如果我们不借助select来实现的话,其实可以大致做到,但结果不会令人满意。
// 代码段8fun main() = runBlocking {val startTime = System.currentTimeMillis()val channel1 = produce {send(1)delay(200L)send(2)delay(200L)send(3)delay(150L)}val channel2 = produce {delay(100L)send("a")delay(200L)send("b")delay(200L)send("c")}channel1.consumeEach {println(it)}channel2.consumeEach {println(it)}println("Time cost: ${System.currentTimeMillis() - startTime}")}/*输出结果123abcTime cost: 989*/
可以看到,通过普通的方式,我们的代码是串行执行的,执行结果并不符合预期。channel1执行完毕以后,才会执行channel2,程序总体的执行时间,也是两者的总和。最关键的是,如果channel1当中如果迟迟没有数据的话,我们的程序会一直卡着不执行。
当然,以上的问题,我们通过其他方式也可以解决,但最方便的解决方案,还是select。让我们来看看select与Channel搭配后,会带来什么样的好处。
// 代码段9fun main() = runBlocking {val startTime = System.currentTimeMillis()val channel1 = produce {send("1")delay(200L)send("2")delay(200L)send("3")delay(150L)}val channel2 = produce {delay(100L)send("a")delay(200L)send("b")delay(200L)send("c")}suspend fun selectChannel(channel1: ReceiveChannel<String>, channel2: ReceiveChannel<String>): String = select<String> {// 1, 选择channel1channel1.onReceive{it.also { println(it) }}// 2, 选择channel1channel2.onReceive{it.also { println(it) }}}repeat(6){// 3, 选择6次结果selectChannel(channel1, channel2)}println("Time cost: ${System.currentTimeMillis() - startTime}")}/*输出结果1a2b3cTime cost: 540*/
从程序的执行结果中,我们可以看到,程序的输出结果符合预期,同时它的执行耗时,也比代码段8要少很多。上面的代码中有几个注释,我们来看看:
- 注释1和2,onReceive{} 是Channel在select当中的语法,当Channel当中有数据以后,它就会被回调,通过这个Lambda,我们也可以将结果传出去。
- 注释3,这里我们执行了6次select,目的是要把两个管道中的所有数据都消耗掉。管道1有3个数据、管道2有3个数据,所以加起来,我们需要选择6次。
这时候,假设channel1出了问题,它不再产生数据了,我们看看程序会怎么样执行。
// 代码段10fun main() = runBlocking {val startTime = System.currentTimeMillis()val channel1 = produce<String> {// 变化在这里delay(15000L)}val channel2 = produce {delay(100L)send("a")delay(200L)send("b")delay(200L)send("c")}suspend fun selectChannel(channel1: ReceiveChannel<String>, channel2: ReceiveChannel<String>): String = select<String> {channel1.onReceive{it.also { println(it) }}channel2.onReceive{it.also { println(it) }}}// 变化在这里repeat(3){selectChannel(channel1, channel2)}println("Time cost: ${System.currentTimeMillis() - startTime}")}/*输出结果abcTime cost: 533*/
在上面的代码中,我们将channel1当中的send()都删除了,并且,repeat()的次数变成了3次,因为管道里只有三个数据了。
这时候,我们发现,select也是可以正常执行的。
不过,我们有时候可能并不清楚每个Channel当中有多少个数据,比如说,这里如果我们还是写repeat(6)的话,程序就会出问题了。
// 代码段11// 仅改动这里repeat(6){selectChannel(channel1, channel2)}/*崩溃:Exception in thread "main" ClosedReceiveChannelException: Channel was closed*/
这时候,你应该就能反应过来了,由于我们的channel2当中只有3个数据,它发送完数据以后就会被关闭,而我们的select是会被调用6次的,所以就会触发上面的ClosedReceiveChannelException异常。
在19讲当中,我们学过receiveCatching()这个方法,它可以封装Channel的结果,防止出现ClosedReceiveChannelException。类似的,当Channel与select配合的时候,我们可以使用onReceiveCatching{} 这个高阶函数。
// 代码段12fun main() = runBlocking {val startTime = System.currentTimeMillis()val channel1 = produce<String> {delay(15000L)}val channel2 = produce {delay(100L)send("a")delay(200L)send("b")delay(200L)send("c")}suspend fun selectChannel(channel1: ReceiveChannel<String>, channel2: ReceiveChannel<String>): String =select<String> {channel1.onReceiveCatching {it.getOrNull() ?: "channel1 is closed!"}channel2.onReceiveCatching {it.getOrNull() ?: "channel2 is closed!"}}repeat(6) {val result = selectChannel(channel1, channel2)println(result)}println("Time cost: ${System.currentTimeMillis() - startTime}")}/*输出结果abcchannel2 is closed!channel2 is closed!channel2 is closed!Time cost: 541程序不会立即退出*/
这时候,即使我们不知道管道里有多少个数据,我们也不用担心崩溃的问题了。在onReceiveCatching{} 这个高阶函数当中,我们可以使用it.getOrNull()来获取管道里的数据,如果获取的结果是null,就代表管道已经被关闭了。
不过,上面的代码仍然还有一个问题,那就是,当我们得到所有结果以后,程序不会立即退出,因为我们的channel1一直在delay()。这时候,当我们完成6次repeat()调用以后,我们将channel1、channel2取消即可。
// 代码段13fun main() = runBlocking {val startTime = System.currentTimeMillis()val channel1 = produce<String> {delay(15000L)}val channel2 = produce {delay(100L)send("a")delay(200L)send("b")delay(200L)send("c")}suspend fun selectChannel(channel1: ReceiveChannel<String>, channel2: ReceiveChannel<String>): String =select<String> {channel1.onReceiveCatching {it.getOrNull() ?: "channel1 is closed!"}channel2.onReceiveCatching {it.getOrNull() ?: "channel2 is closed!"}}repeat(6) {val result = selectChannel(channel1, channel2)println(result)}// 变化在这里channel1.cancel()channel2.cancel()println("Time cost: ${System.currentTimeMillis() - startTime}")}
这时候,我们对比一下代码段13和代码段10的话,就会发现程序的执行效率提升的同时,扩展性和灵活性也更好了。
提示:这种将多路数据以非阻塞的方式合并成一路数据的模式,在其他领域也有广泛的应用,比如说操作系统、Java NIO(Non-blocking I/O),等等。如果你能理解这个案例中的代码,相信你对操作系统、NIO之类的技术也会有一个新的认识。
思考与实战
如果你足够细心的话,你会发现,当我们的Deferred、Channel与select配合的时候,它们原本的API会多一个on前缀。
public interface Deferred : CoroutineContext.Element {public suspend fun join()public suspend fun await(): T// select相关public val onJoin: SelectClause0public val onAwait: SelectClause1<T>}public interface SendChannel<in E>public suspend fun send(element: E)// select相关public val onSend: SelectClause2<E, SendChannel<E>>}public interface ReceiveChannel<out E> {public suspend fun receive(): Epublic suspend fun receiveCatching(): ChannelResult<E>// select相关public val onReceive: SelectClause1<E>public val onReceiveCatching: SelectClause1<ChannelResult<E>>}
所以,只要你记住了Deferred、Channel的API,你是不需要额外记忆select的API的,只需要在原本的API的前面加上一个on就行了。
另外你要注意,当select与Deferred结合使用的时候,当并行的Deferred比较多的时候,你往往需要在得到一个最快的结果以后,去取消其他的Deferred。
比如说,对于Deferred1、Deferred2、Deferred3、Deferred4、Deferred5,其中Deferred2返回的结果最快,这时候,我们往往会希望取消其他的Deferred,以节省资源。那么在这个时候,我们可以使用类似这样的方式:
fun main() = runBlocking {suspend fun <T> fastest(vararg deferreds: Deferred<T>): T = select {fun cancelAll() = deferreds.forEach { it.cancel() }for (deferred in deferreds) {deferred.onAwait {cancelAll()it}}}val deferred1 = async {delay(100L)println("done1") // 没机会执行"result1"}val deferred2 = async {delay(50L)println("done2")"result2"}val deferred3 = async {delay(10000L)println("done3") // 没机会执行"result3"}val deferred4 = async {delay(2000L)println("done4") // 没机会执行"result4"}val deferred5 = async {delay(14000L)println("done5") // 没机会执行"result5"}val result = fastest(deferred1, deferred2, deferred3, deferred4, deferred5)println(result)}/*输出结果done2result2*/
所以,借助这样的方式,我们不仅可以通过async并发执行协程,也可以借助select得到最快的结果,而且,还可以避免不必要的资源浪费。
小结
好,这节课的内容就到这儿了,我们来做一个简单的总结。
- select,就是选择“更快的结果”。
- 当select与async、Channel搭配以后,我们可以并发执行协程任务,以此大大提升程序的执行效率甚至用户体验,并且还可以改善程序的扩展性、灵活性。
- 关于select的API,我们完全不需要去刻意记忆,只需要在Deferred、Channel的API基础上加上on这个前缀即可。
- 最后,我们还结合实战,分析了select与async产生太多并发协程的时候,还可以定义一个类似fastest()的方法,去统一取消剩余的协程任务。这样的做法,就可以大大节省计算资源,从而平衡性能与功耗。
其实,和Kotlin的Channel一样,select并不是Kotlin独创的概念。select在很多编程语言当中都有类似的实现,比如Go、Rust,等等。在这些计算机语言当中,select的语法可能与Kotlin的不太一样,但背后的核心理念都是“选择更快的结果”。
所以,只要你掌握了Kotlin的select,今后学习其他编程语言的select,都不再是问题。
思考题
前面我们已经说过,select的API,只需要在Deferred、Channel原本API的基础上加一个on前缀即可。比如onAwait{}。那么,你有没有觉得它跟我们前面学的onStart{}、onCompletion{} 之类的回调API很像?
你能从中悟出select的实现原理吗? 欢迎在留言区说说你的想法,也欢迎你把今天的内容分享给更多的朋友。