01 | 网络模型和工具:网络为什么要分层?
你好,我是胜辉。
今天是咱们的第一节正课,就像我在开篇词里介绍的,在预习篇这里,我们的目标是搞清楚网络分层的概念,还有初步学习抓包分析。所以接下来,我会先从一些基础的网络知识说起,为你重点讲解网络分层模型以及各层之间的区别和联系。
因为咱们是以案例实战为导向的课程,所以我除了会在网络的每一层,给你介绍相关的技术细节以外,还会带你认识相应的排查工具。学完这节课,哪怕你原本是网络方面的小白,你也可以在网络排查方面“一试身手”了,是不是有点期待了呢?好,让我们开始吧。
网络是七层、五层还是四层?
学习网络排查,可能首先要搞清楚的,就是网络的分层模型了。工作中,我们也时常会听到这些术语,比如三层交换机、七层规则等等。网络分层的概念,可谓深入人心。
可是你有没有想过,网络为什么要分层呢?难道是非分不可吗?回答这个问题之前,我们先做个有趣的假设:这会儿是在网络诞生的前夜,什么IP协议、TCP协议都还不存在,而你是网络的缔造者,面临设计网络这个伟大的任务。面对这么好的机会,你会选择做怎样的设计呢?
你大体上有这么两种选择:
- **应用程序包办一切。**程序把应用层的数据,按某种编码转化为二进制数据,然后程序去操控网卡,把二进制数据发送到网络上。这期间,通信的连接方式、传输的可靠性、速度和效率的保证等等,都需要这个程序去实现。然后下次开发另外一个应用的时候,就把上面这些活,再干一遍。
- **应用程序、操作系统、网络设备等环节各自分工。**应用程序只负责实现应用层的业务逻辑,操作系统负责连接的建立、处理网络拥塞和丢包乱序、优化网络读写速度等等,然后把数据交给网卡,后者和交换机等设备做好联动,负责二进制数据在物理线路上的传送和接收。
那么显然,第一种大包大揽的方式,实现难度太大、耦合度太高,怎么看都是一个“反面典型”。所以,我们应该选择第二种,也就是分层的方式去实现。
你有没有发现,其实这个思路,跟编程的思想是类似的。在编程中,我们需要把一些逻辑抽象为函数或者对象,以实现更好的解耦和复用。在网络世界里也是如此,每一层干好自己的分内事,那么所有的层次配合起来工作的时候,就显得有条不紊了。
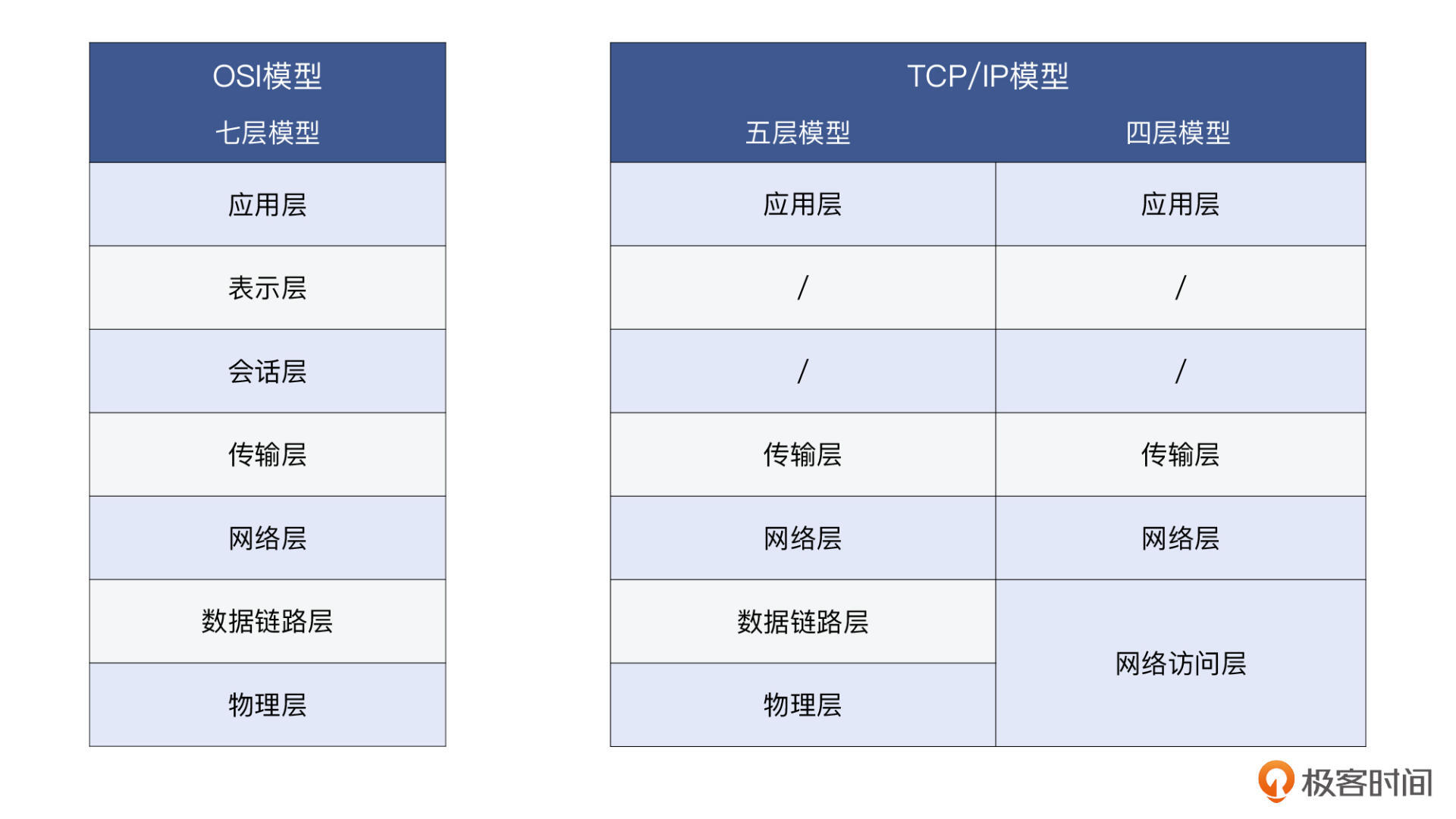
说到具体的分层模型,你应该会想到两种比较有名的方案。对,它们就是OSI的七层模型,和TCP/IP的四层/五层模型。这两种模型的最大区别,就是前者在传输层和应用层之间,还有会话层和表示层,而后者没有。
我们来看一下示意图:
那在这里,你可能还会想:这两种模型哪种用得最多,或者说,哪种更合理呢?
其实我觉得倒不用过于纠结在“谁比谁更好”这个点上,如果我们理解了每一层的作用,那么就不会被表象上的层级所束缚了。事实上,两种分法都有可取之处。
一般来说,七层模型在我们工作当中谈论得更多些。比如,我的同事会找过来说“你帮我建一个七层规则吧”。这里的七层,就是指应用层,他说的“七层规则”呢,可能是HTTP路由规则,比如把符合某种条件的HTTP请求,分流到某个特定的后端集群。
还有一些场景,也是比较适合用七层模型来解释的。比如,TLS虽然在TCP之上,按TCP/IP模型就要被归入应用层。但事实上,在HTTPS的场景下,HTTP协议就是运行在TLS协议之上的,那么是不是把HTTP和TLS分到不同的层次更合适呢?正好在七层模型里,第五层和第六层,可以分别代表TLS的会话保持功能和数据加解密这种表示层的功能。
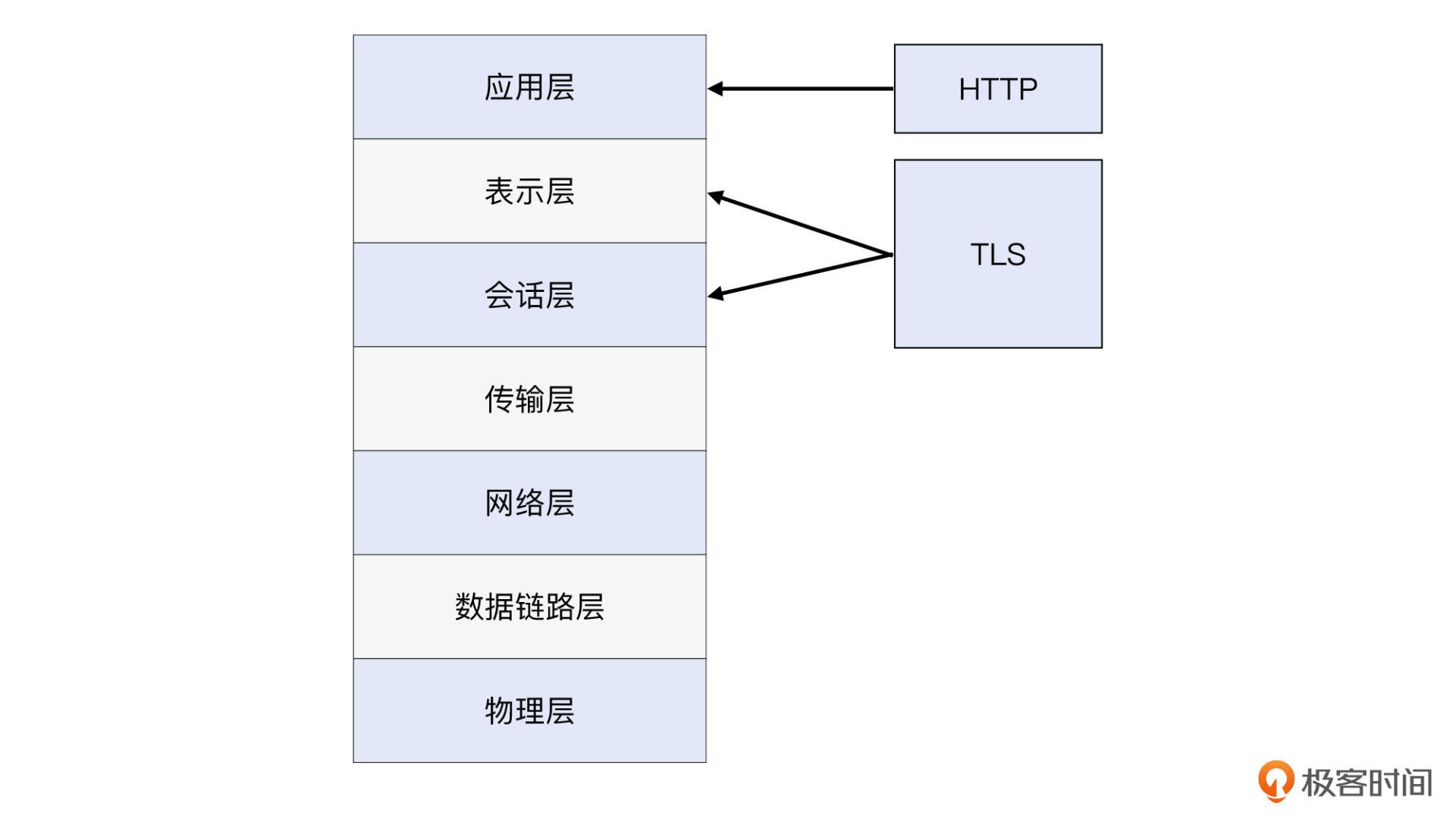
不过,会话层和表示层的协议确实比较少。从控制模型复杂度的角度来看,如果把这两层都合并到应用层,那么模型倒是比较简单,也适合入门学习的。所以从这一点上看,TCP/IP模型也有可取之处。
这里你可能稍有疑问,为什么TCP/IP还有四层和五层模型这两种说法呢?其实五层模型就是OSI的前四层,加上一个应用层。这样的话,这个五层模型跟OSI七层模型,差异就比四层模型又缩小了一点。
所以,你现在应该明白了,**两种分层模型的最大差异,其实还是在会话层和表示层上面。**第一到第四层,已经基本统一了。而它们的最高层,虽然一个叫第七层,一个叫第四层或者第五层,表面上虽然并不一致,但实际上都可以用“应用层”来代替。这样既避免了可能的误解,也更加准确地表示了这一层的具体用途。
什么是TCP流?
在一些技术文档,特别是Wireshark相关的文档中,“TCP流”是一个很常见的词汇。它是什么意思呢?为什么叫“流”,难道跟水有关吗?
其实,这里的TCP流,就是英文的TCP Stream。Stream这个词有“流”的意思,也有“连续的事件”这样一个含义,所以它是有前后、有顺序的,这也正对应了TCP的特性。
跟Stream相对的一个词是Datagram,它是指没有前后关系的数据单元,比如UDP和IP都属于Datagram。在Linux网络编程里面,TCP对应的socket类型是SOCK_STREAM,而UDP对应的,就是SOCK_DGRAM了。显然,DGRAM就是Datagram的简写。
在具体的网络报文层面,一个TCP流,对应的就是一个五元组:传输协议类型、源IP、源端口、目的IP、目的端口。比如,今天你访问了极客时间网站,那么你这次的TCP流就可能就是这样一个五元组:
(TCP, your_ip, your_port, geekbang_ip, 443)
一个IP报文,包含了所有这五个元素,所以Wireshark在解析抓包文件时,自然就能通过五元组知道每个报文所属的TCP流了。这也是为什么我们可以在Wireshark里,用Follow TCP Stream的方法,找到报文所在的TCP流。
不过有时候,也会有四元组的说法。其实它跟五元组大体上是一致的,只是四元组没有区分传输层协议类型(TCP或者UDP)。但是如果我们都清楚地知道应用类型,比如知道应用是HTTP协议的,那它的传输层协议默认就是TCP,这一元是否算在里面,已经不重要了。
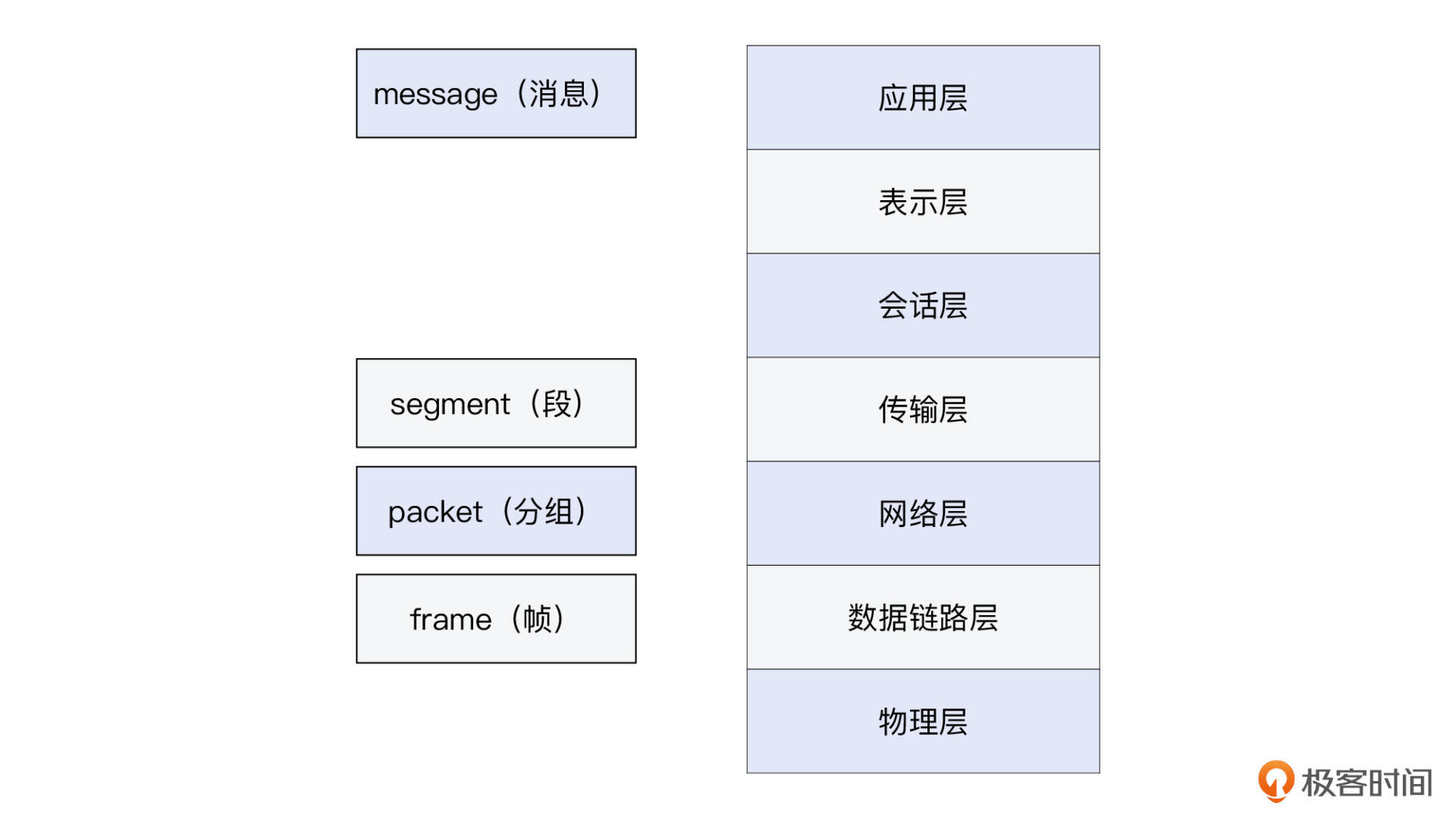
报文、帧、分组、段、数据包,这些术语是同一个东西吗?
报文(packet),是一种相对宽泛和通用的说法,基本上每一层都可以用。比如,在应用层,你可以说“HTTP报文”;在传输层,你可以说“TCP报文”;同样的,在网络层,当然就是“IP报文”了。事实上,网络层也是“报文”一词被使用最多的场景了。数据包也是类似的,可以在很多场景下通用。
我们再稍微考究一下语法。packet这个词的后缀是et。而在英文中,以et结尾的很多词表示某一个小小的东西。比如功能完备的一小段代码,叫code snippet,一小段内嵌在HTML中的Java前端代码,叫applet。自然的,packet就是一个小的pack(包裹)。
然而,另外几个术语在用的时候,就需要讲究一点了,因为它们并不是通用词,而是特定层的专有词汇。
**帧(frame)**是二层也就是数据链路层的概念,代表了二层报文,它包含帧头、载荷、帧尾。注意,帧是有尾部的,而其他像IP、TCP、HTTP等层级的报文,都没有尾部。我们不可以说“TCP帧”或者“IP帧”,虽然也许对方也明白你的意思,但我们都想做得专业一点,不是嘛。这里还有个小知识点:HTTP/2实现了多路复用,其中也有帧的概念,不过那个帧,跟这里网络二层的帧,除了名称相同以外,就没有别的联系了。
分组是IP层报文,也就是狭义的packet。
段特指TCP segment,也就是TCP报文。既然segment是“部分”的意思,那这个“整体”又是什么呢?它就是在应用层交付给传输层的消息(message)。当message被交付给传输层时,如果这个message的原始尺寸,超出了传输层数据单元的限制(比如超出了TCP的MSS),它就会被划分为多个segment。这个过程就是分段(segmentation),也是TCP层的一个很重要的职责。
说到segmentation,你可能也会想到fragmentation(分片)。这俩是同一个东西吗?这方面的知识点也不少,我在这里就不具体展开了。不过别着急,我会在第8讲里,帮你把这两个东西梳理清楚。
另外,这里还要提一下,Datagram的中文叫**“数据报”**,但不是“数据包”。读音类似,但意思并不完全相同。前面说过,“数据包”是一个通用词,所以用“UDP数据包”指代“UDP数据报”并没有问题。但反过来,非UDP协议的数据包,比如TCP段,就不能叫“TCP数据报”了,因为TCP不是Datagram。
最后,你可以再来看下这张层级和术语对应关系的示意图:
网络各层都有哪些排查工具呢?
通过上面的内容,你应该对于网络为什么要做分层、为什么那样做分层,已经有了比较清晰地认识了,我也带你探讨了每个层级的名词概念。所谓“名不正则言不顺”,咱们把这些术语搞清楚了,是不是感觉自己的技术“格调”也有那么点提升了呢?
接下来,我们进入干货部分,也就是每个层级的排查工具,用大白话说就是:“这可是我们吃饭的家伙儿”。
应用层
应用层的排查工具就太多了,相信做应用的同学,对自己的应用排查,应该是比我要更加熟悉。那我这里呢,就选一个主要的应用来展开吧,我们来谈谈 HTTP应用的排查工具。
现在主流的浏览器是Google的Chrome,它本身就内置了一个开发者工具。在Chrome界面里按下F12,或者你是苹果系统的话,还可以按下组合键option + command + I,启动开发者工具。
其实在其他的浏览器上,都有类似这样的工具,比如Firefox和Edge。而且因为Edge基于Chromium浏览器内核,它的开发者工具跟Chrome的开发者工具很相似。
在更老的IE浏览器时代,并没有原生的开发者工具。当时有一个叫HttpWatch的工具,可以在IE上实现类似的功能,但需要另外安装。
借助开发者工具,我们可以非常方便地做很多事,比如以下这些。
- 找到有问题的服务端IP
比如有用户报告死活访问不了你的网站,但是你很清楚这个网站的域名对应了很多IP地址,你怎么知道用户连的是哪个IP呢?
你可以这样做:让客户启用开发者工具,在Network页找到主页对象,在它的Headers部分,就能看到Remote address,这里的IP就是当前连接的IP,比如下面这样:
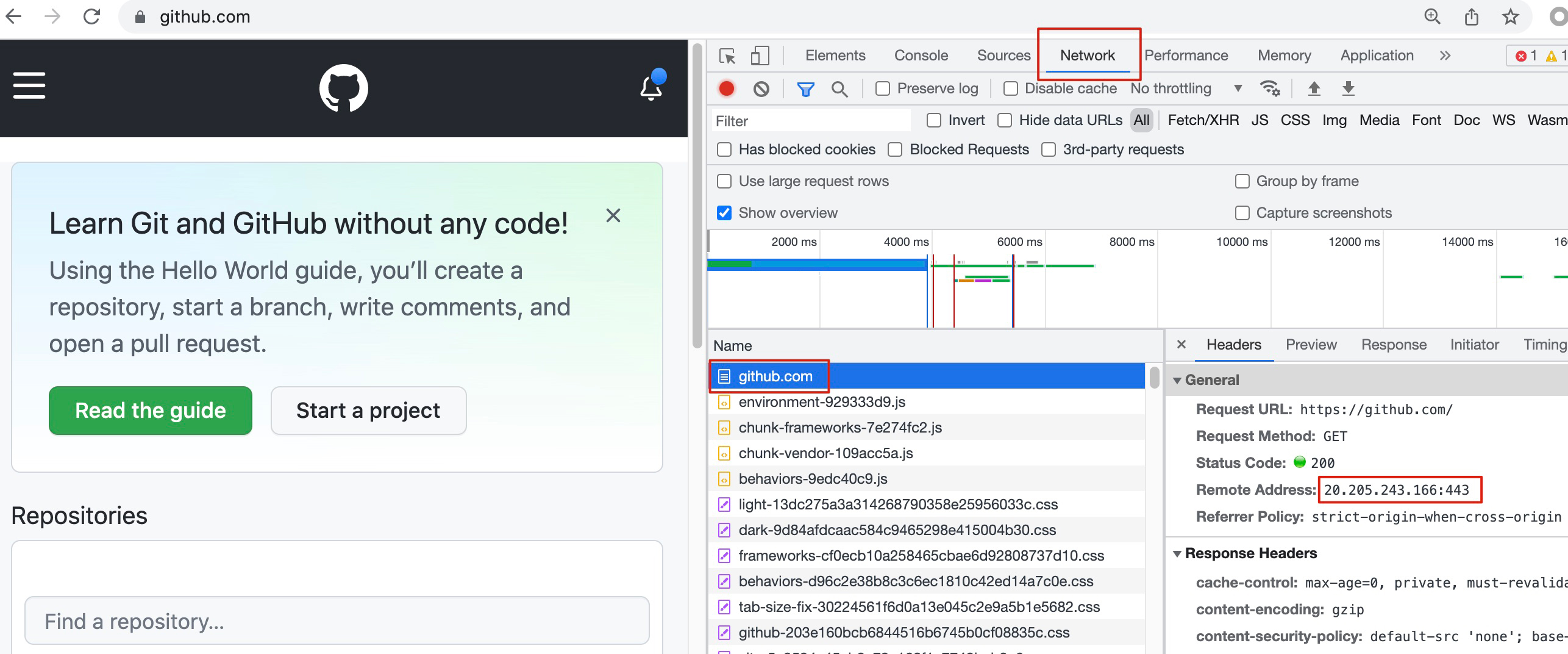
不过有句成语叫“刻舟求剑”,因为DNS解析的关系,你很可能下次重连就不是这个IP了,所以每次都应该重新确认一下这个信息。
这个技巧,在排查公网的访问问题的时候特别有用。要知道,现在流量大一点的网站都已经上了CDN,那就必然在全国乃至全球各地,有少则数十个、多则数百个CDN终端节点,在给访问者提供就近的服务。如果有人说他访问不了某个站点了,那么请一定让他用开发者工具,找到他连的远程IP,然后你再根据这个信息展开排查工作。
- 辅助排查网页慢的问题
访问页面感觉很慢,那么可以借助开发者工具的时间统计功能,找到耗时较高的HTTP资源对象,再针对性排查。比如我觉得访问https://github.com很慢,那么可以先打开开发者工具,然后访问站点,等全部加载完成后,到Network页查看这些HTTP对象的加载时间。
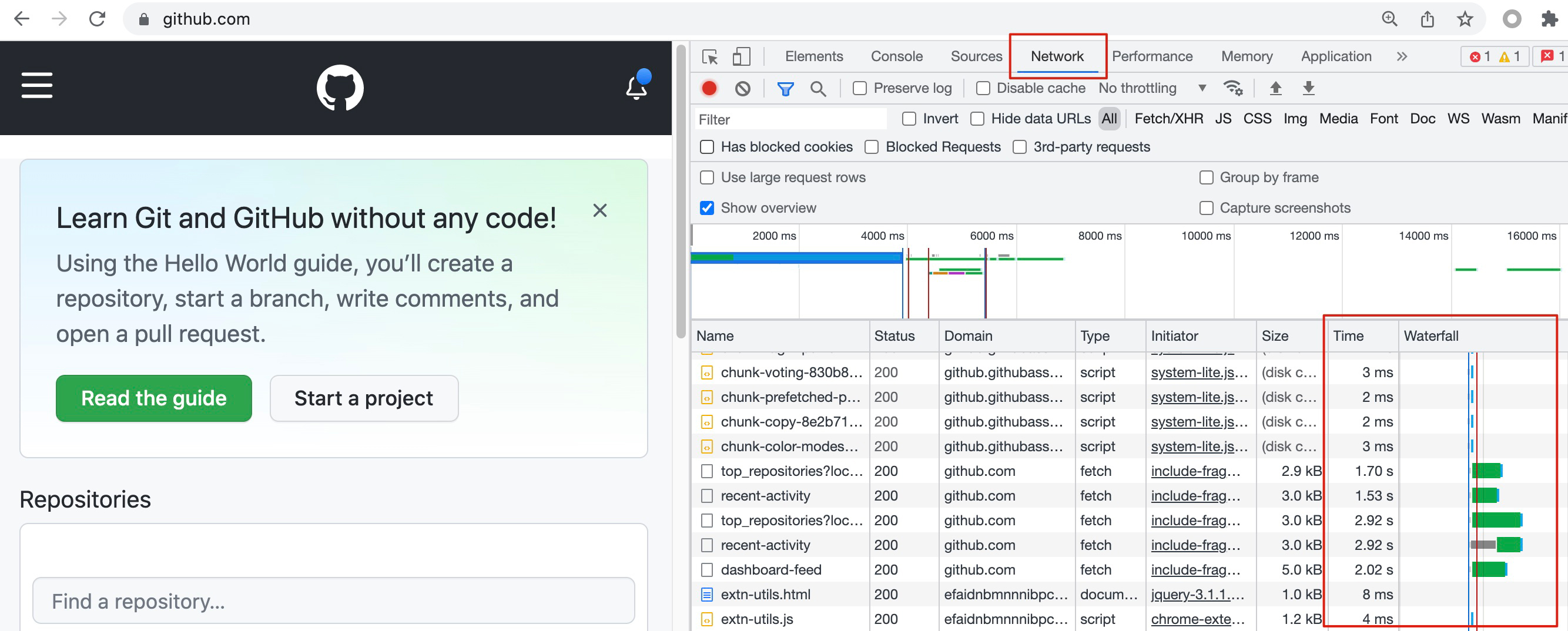
不过,这个办法只能排查到是哪个资源对象耗时比较长,但更进一步的排查,比如“为什么这个对象的加载时间比别的对象长”这个问题,开发者工具就难以回答了。关于这个问题,我会在后续的课程里深入展开,我们会用到抓包分析这把“手术刀”,来根本性地排查这类问题。
- 解决失效Cookie带来的问题
有时候我们的Cookie过期了,导致无法正常登录站点,那么可以打开开发者工具,到Application页,找到Storage -> Cookie,把对应的条目清除。这样下次你再访问这个站点,就已经“洗心革面”了。对站点来说,你就是一次新的访问,可以生成一次新的Cookie了。
当然,你通过删除浏览器缓存的方式,也是可以做到这一点的。但开发者工具的优点是,可以细粒度到这个网站级别,而删除缓存的方式,删除的就是所有站点的Cookie了,这未必是你想要的。
表示层和会话层
在前面的网络分层部分,我提到过,其实表示层和会话层的协议并不多,TLS可以归入这两个层级。为了对TLS的问题进行排查,我推荐你两种工具。
**第一种,还是基于浏览器做初步的检查,主要是围绕证书本身做检查。**在浏览器的地址栏那里,有一个按钮,点开后就可以查看TLS证书等信息:
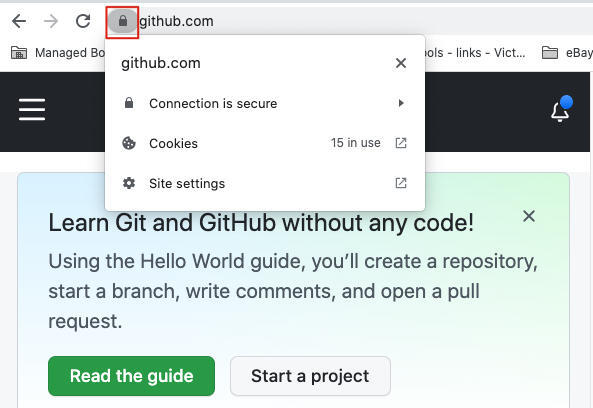
在上面的菜单中,继续点开Connection is secure按钮,进而点击Certificate is valid按钮,就能查看证书了。
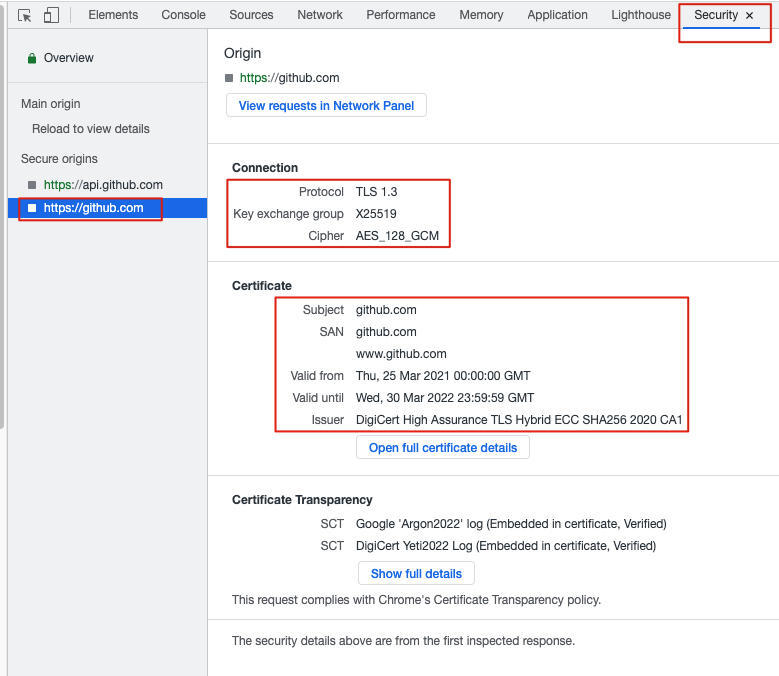
另外,使用开发者工具的Security菜单,还可以查看更为详细的TLS信息,包括协议版本、密钥交换算法、证书有效期等等。
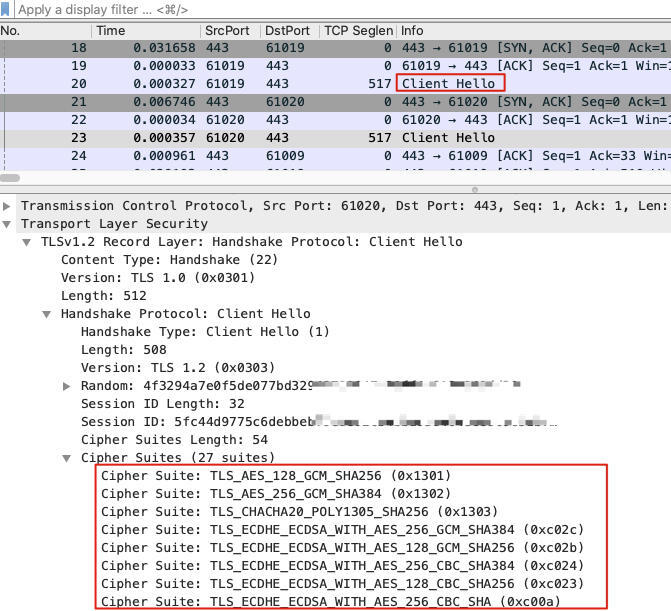
**第二种,关于TLS握手、密钥交换、密文传输等方面的排查,还是需要用tcpdump和Wireshark来做。**在Wireshark中,可以更加全面地查看TLS细节。
比如,我们可以直接看到TLS握手阶段里,双方协商过程中各自展示的Cipher suite,而在开发者工具里,我们只能看到协商完成后的选择。
传输层
传输层毫无疑问是重中之重,工具也很多。我们就按排查场景来介绍工具。
- 路径可达性测试
如果我们要测试TCP握手,我们有telnet、nc这两个常规工具。比如telnet:
$ telnet www.baidu.com 443Trying 180.101.49.12...Connected to www.a.shifen.com.Escape character is '^]'.
用nc呢,可以这样:
$ nc -w 2 -zv www.baidu.com 443Connection to www.baidu.com 443 port [tcp/https] succeeded!
- 查看当前连接状况
netstat 命令是一个经典命令了,很多同学都会使用它来获取当前的TCP、UDP等的连接信息,比如:
$ netstat -antActive Internet connections (servers and established)Proto Recv-Q Send-Q Local Address Foreign Address Statetcp 0 0 127.0.0.53:53 0.0.0.0:* LISTENtcp 0 0 0.0.0.0:22 0.0.0.0:* LISTENtcp 0 0 0.0.0.0:80 0.0.0.0:* LISTENtcp 0 280 10.0.2.15:22 10.0.2.2:56669 ESTABLISHEDtcp6 0 0 :::22 :::* LISTEN
- 查看当前连接的传输速率
有时候,你的网络跑得挺繁忙的,但你却不知道哪个连接占用了大量的带宽?你可以用 iftop。这个工具不是系统默认自带的,需要你安装一下,然后执行iftop就好了。对了,你需要有sudo权限,也就是执行sudo iftop,然后就能看到不同连接的传输速率,把祸害你带宽的连接给找到。比如下面这样:
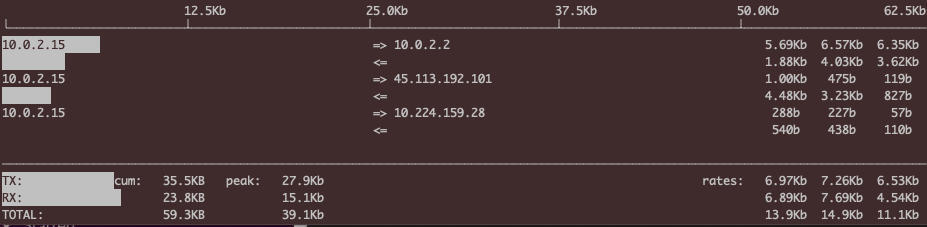
- 查看丢包和乱序等的统计
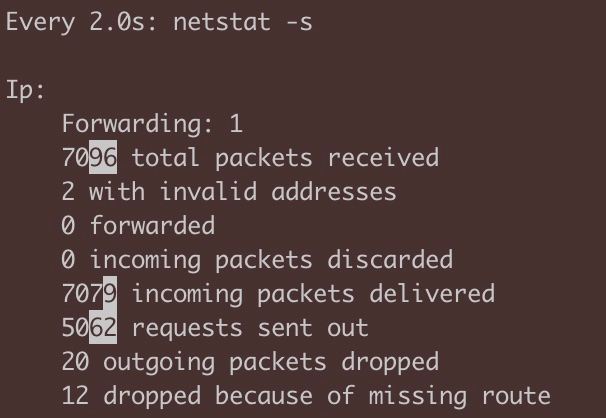
其实,用netstat除了可以获取实时连接状况,还可以获取历史统计信息。比如,你怀疑一台机器的网络很不稳定,除了用ping做简单的测试,你还可以用 netstat -s 来获取更加详细的统计信息。比如,其中的TCP丢包和乱序计数值,就能帮助你判断传输层的状况。下面是我截取了一次netstat -s命令的输出:
$ netstat -s......Tcp:16 active connection openings1 passive connection openings8 failed connection attempts1 connection resets received1 connections established6254 segments received4035 segments sent out1 segments retransmitted0 bad segments received3 resets sent......TcpExt:1 ICMP packets dropped because socket was locked3 TCP sockets finished time wait in fast timer8 delayed acks sent4674 packet headers predicted10 acknowledgments not containing data payload received1008 predicted acknowledgmentsTCPTimeouts: 1TCPBacklogCoalesce: 1401 connections reset due to early user closeTCPRcvCoalesce: 2187TCPAutoCorking: 110TCPSynRetrans: 1TCPOrigDataSent: 1041TCPDelivered: 1049
你可能会问:这些不是静态值吗,我想知道当前情况啊?这个也很好解决,你可以这样做:
watch --diff netstat -s
这个命令会把发生变化的数值进行高亮,方便我们查看:
当然,上面这个算运维“青铜”版。你也可以写一个简单的脚本,在两次netstat -s命令之间执行sleep,然后计算两个读数之间的差值,并除以sleep的时间,得到大致的变化速度。这样就又升级了一点。
如果你想做得再到位一点,你可以把netstat -s的输出值写入到TSDB,然后用Grafana之类的Dashboard展示,这样不仅有视图,也有历史值,可以算运维“王者”了。
- 还有ss?
ss 命令是Iproute2包里的命令,也是netstat的“取代者”。它提供了对socket的丰富的统计信息。比如下面这条命令我也经常用,可以查看到当前连接的统计信息:
$ ss -sTotal: 164TCP: 5 (estab 1, closed 0, orphaned 0, timewait 0)Transport Total IP IPv6RAW 1 0 1UDP 2 2 0TCP 5 4 1INET 8 6 2FRAG 0 0 0
当然,也不能完全说“ss等于netstat”,因为事实上netstat命令的功能,被拆分到了ss和ip这两个命令里,并分别得到了丰富和加强。具体的细节,我们在课程中还会陆续提到。
网络层
在这一层,除了可以直接用ping这个非常简便的工具以外,你还应该掌握另外两个命令,它们能提供更为强大的排查能力,它们就是traceroute和mtr。
- 查看网络路径状况
下面这个,是我用自己的Mac笔记本做一个简单的traceroute的典型输出:
$ traceroute www.baidu.comtraceroute to www.a.shifen.com (180.101.49.12), 64 hops max1 10.0.2.2 0.133ms 0.131ms 0.087ms2 192.168.1.1 3.048ms 1.466ms 1.574ms3 100.65.0.1 8.975ms 3.067ms 6.472ms4 61.152.53.149 5.644ms 3.691ms 4.624ms5 61.152.24.226 5.357ms 4.393ms 4.244ms6 202.97.29.122 10.171ms 10.403ms 8.755ms7 58.213.94.118 10.707ms 11.880ms 11.441ms8 58.213.94.90 9.644ms * *9 58.213.96.110 12.758ms 12.095ms 11.842ms10 * * *11 * * *12 * * *13 * * *14 * * *15 * * *16 * * *17 * * *18 * * *19 * * *20 * * *
哦,等等,为什么从第10跳开始就没有IP,只有星号了?你是不是也遇到过这种情况呢?其实,你稍微改一下命令,也就是加上**-I**参数(I代表ICMP),就可以正常跑到底了:
$ traceroute www.baidu.com -Itraceroute to www.a.shifen.com (180.101.49.12), 64 hops max1 10.0.2.2 0.099ms 2.363ms 0.078ms2 192.168.1.1 3.320ms 1.220ms 1.204ms3 100.65.0.1 8.737ms 4.872ms 6.403ms4 61.152.54.125 5.035ms 3.397ms 4.288ms5 * 61.152.25.110 4.176ms *6 202.97.101.30 7.447ms 6.399ms 5.936ms7 58.213.95.110 10.488ms * 9.014ms8 * 58.213.95.134 11.064ms *9 58.213.96.74 10.997ms 10.042ms 10.592ms10 * * *11 * * *12 * * *13 180.101.49.12 11.269ms 9.518ms 8.779ms
背后的原理,就是traceroute默认是用UDP作为探测协议的,但是很多网络设备并不会对UDP作出回应。所以我们改成ICMP协议做探测后,网络设备就有回应了。其实,Windows上的tracert,就是默认用ICMP,这一点跟Linux正好是反过来的。两个操作系统,真是“相爱相杀”啊。
但是,traceroute也有一个明显的不足:它不能对这个路径做连续多次的探测。
于是,mtr出现了,它可以说是traceroute的超集,除了traceroute的功能,还能实现丰富的探测报告。尤其是它对每一跳的丢包率的百分比,是用来定位路径中节点问题的重要指标。所以,当你在遇到**“连接状况时好时坏的问题”**的时候,单纯用一次性的traceroute恐怕难以看清楚,那就可以用mtr,来获取更加全面和动态的链路状态信息了。
$ mtr www.baidu.com -r -c 10Start: 2022-01-07T04:05:02+0000HOST: victorebpf Loss% Snt Last Avg Best Wrst StDev1.|-- _gateway 0.0% 10 0.3 0.4 0.2 1.2 0.32.|-- 192.168.1.1 0.0% 10 1.6 1.8 1.4 3.2 0.53.|-- 100.65.0.1 0.0% 10 3.8 7.0 3.8 10.3 2.04.|-- 61.152.54.125 0.0% 10 4.0 4.3 3.6 5.1 0.55.|-- 61.152.25.110 30.0% 10 5.0 6.8 4.4 18.9 5.46.|-- 202.97.101.30 20.0% 10 7.8 6.6 5.4 7.8 0.87.|-- 58.213.95.110 80.0% 10 10.0 9.8 9.6 10.0 0.38.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.09.|-- 58.213.96.74 0.0% 10 10.5 12.7 9.9 24.7 4.910.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.011.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.012.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.013.|-- 180.101.49.12 0.0% 10 9.4 9.1 8.3 9.7 0.5
- 查看路由
命令 route 可以查看路由表,不过这个命令比较老一点:
# route -nKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Iface0.0.0.0 10.0.2.2 0.0.0.0 UG 100 0 0 enp0s310.0.2.0 0.0.0.0 255.255.255.0 U 0 0 0 enp0s310.0.2.2 0.0.0.0 255.255.255.255 UH 100 0 0 enp0s3172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
传输层工具里介绍的 netstat,其实也能帮我们查看路由,只要加上 -r 参数:
$ netstat -rKernel IP routing tableDestination Gateway Genmask Flags MSS Window irtt Ifacedefault _gateway 0.0.0.0 UG 0 0 0 enp0s310.0.2.0 0.0.0.0 255.255.255.0 U 0 0 0 enp0s3_gateway 0.0.0.0 255.255.255.255 UH 0 0 0 enp0s3172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
我前面说过,netstat是被ss和ip这两个命令替代了。所以我们同样可以用 ip命令查看路由。比如这样:
$ ip routedefault via 10.0.2.2 dev enp0s3 proto dhcp src 10.0.2.15 metric 10010.0.2.0/24 dev enp0s3 proto kernel scope link src 10.0.2.1510.0.2.2 dev enp0s3 proto dhcp scope link src 10.0.2.15 metric 100172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
数据链路层和物理层
这一层离应用层已经很远了,一般来说是专职的网络团队在负责。如果这一层有问题,就会直接体现在网络层表现上面,比如IP会有丢包和延迟等现象,然后会引发传输层异常(如丢包、乱序、重传等)。所以,一个稳定的数据链路层乃至物理层,是网络可靠性的基石。
你可能会奇怪:既然底下这两层的稳定性如此重要,那上层的TCP不是号称还有传输可靠性的保障吗?难道这种保障形同虚设?
其实,这两点并不矛盾。TCP的传输可靠性是通过序列号、确认号、重传机制等来保证的,通过这种机制,TCP可以在一定程度的网络不稳定场景下,依然保证传输可靠,但不等于TCP可以无限容忍底层的不稳定,因为各种TCP拥塞控制算法都会因为这种问题,而极大地降低传输性能。
如果你想查看这两层的状况,可以用 ethtool 这个工具。比如这样:
# ethtool -S enp0s3NIC statistics:rx_packets: 45897tx_packets: 9457rx_bytes: 59125524tx_bytes: 834625rx_broadcast: 0tx_broadcast: 17rx_multicast: 0tx_multicast: 59rx_errors: 0tx_errors: 0tx_dropped: 0
它的原理,是网卡驱动会到内核中注册ethtool回调函数,然后我们用ethtool命令就可以查看这些信息了。由于信息是由网卡驱动提供的,所以十分“接地气”。
如果你在传输层和网络层的排查工具上,已经看到明确的链路不稳定的信息,那就直接找网络团队去处理吧。
小结
这节课,我们回顾了网络分层模型,也了解了OSI模型和TCP/IP模型的区别和联系。通过“抠字眼”的方式,我们把每层的术语搞清楚,由此对分层模型有了更加深入的理解,这个对我们开展网络排查工作,有很强的指导性意义。
然后,我们逐一学习了各层的常用排查工具。我来给你再梳理一下:
- 应用层以HTTP为例,可以用浏览器开发者工具,实现远程IP识别、耗时分析、Cookie删除等需求。
- 会话层和表示层以TLS为主,我们还是用浏览器开发者工具,可以查看证书细节、协商后使用的Cipher suite等信息,属于静态信息。然后学习了用tcpdump和Wireshark 查看更详细的TLS握手细节的方法。这些信息是动态的,也只有用抓包分析的手段才能做到。
- 在传输层,我们学到了 telnet、nc、netstat、ss 等命令,通过它们,我们可以测试连通性,也可以获取连接状况和统计信息,对于传输问题的排查都很有帮助。
- 在网络层及以下的部分,我们学习了 traceroute、mtr、ip 等工具,可以检测网络路径状况。
- 在数据链路层和物理层,我们可以做得不多,主要依靠网络层观察到的链路质量来推断这两次的情况。当然,也可以用 ethtool 这个工具查看这两层的详情。
最后,为了方便你复习,我也给你画了一张思维导图,让你能一目了然:
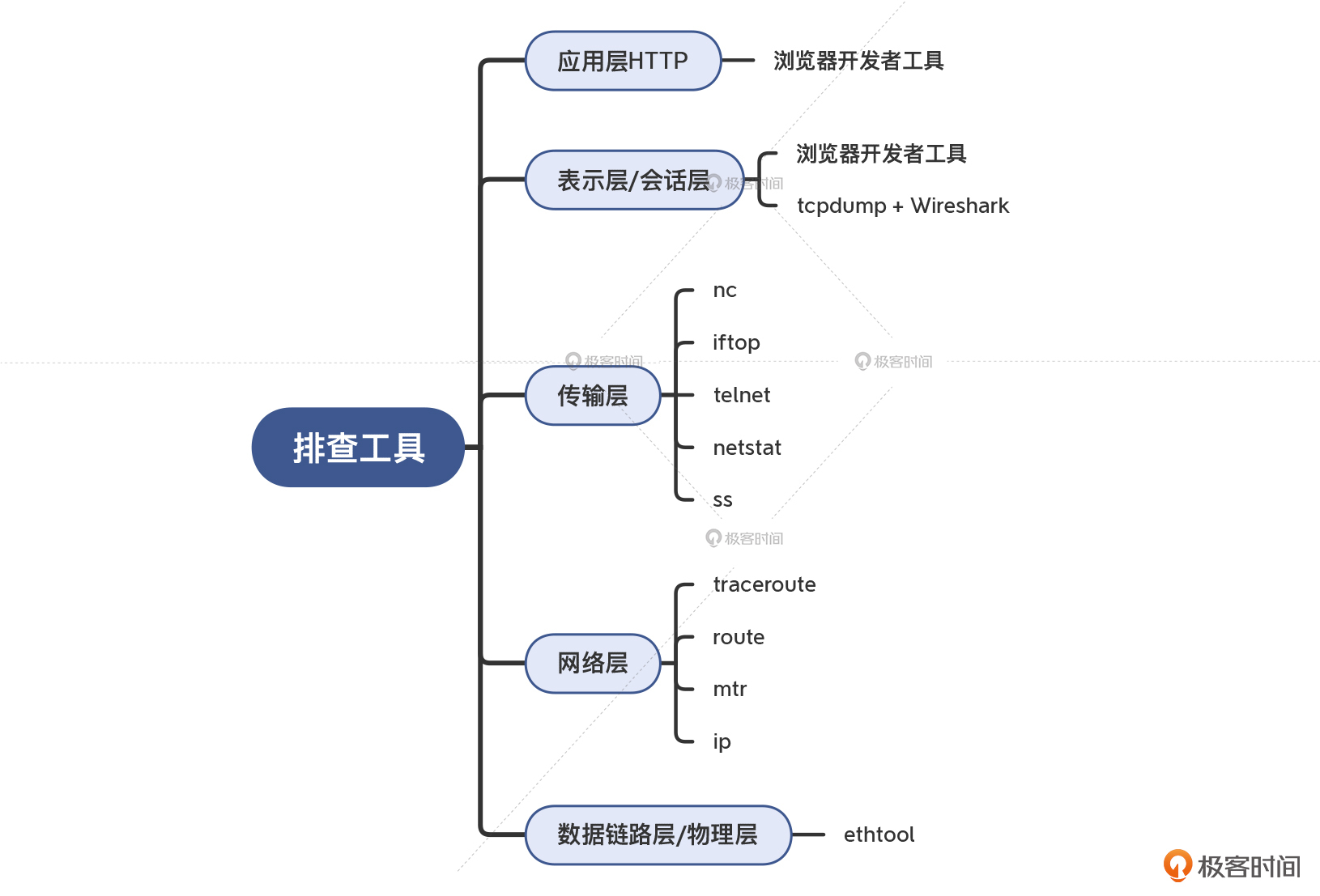
如果对这些命令的更多细节或者原理很感兴趣,在实战三模块里,我也会专门讨论这些工具相关的案例和使用技巧,相信会让你的网络排查技能变得更加丰富多元。
思考题
感谢你认真学完了这节课的内容,不过在结束之前,给你留几道思考题:
- traceroute默认是用UDP来做探测的,那这个又是基于什么原理呢?通和不通,我们会收到怎样的回复?
- 有时候运行telnet后命令就挂起,没有响应了,这说明了什么问题呢?
欢迎你把答案写到留言区,我们一起交流讨论。也欢迎你把今天的内容分享给更多的朋友,一同成长和进步。